[GUIDE] [NSX-T] [PART 1] Troubleshoot poor performance

Récemment, j’ai été confronté à un problème de performance sur un réseau traditionnel à base de PortGroup où j’atteignais des performances de l’ordre de 8 à 9 Gbit/s contre 25 Gbit/s normalement atteignables par la carte physique, et j’ai fait également pu faire le même constat sur de l’overlay avec des débits moyens entre 12 à 14 Gbit/s.
Liste des versions :
ESXi 7.0 U3 20328353
vCenter 7.0 U3 21477706
vCloud Director: 10.3.3.21922251
NSX-T: 3.2.1.2
Ce sujet sera abordé en deux parties. Dans un premier temps, je vais me focaliser sur le network et le storage afin de vérifier qu’il n’y a pas de goulot d’étranglement sur ces deux points via des tests de vérifications assez basiques. Dans un second temps, je vais me concentrer sur la partie NSX-T et les optimisations que peuvent avoir les cartes réseau sur de l’overlay.
Ah oui, et surtout parce qu’il y a plusieurs notions que je souhaite mettre en avant pour pouvoir passer à la partie NSX. Ce sont des notions de bases mais qui, pour certaines, ont été oubliées avec le temps (je l’avoue 😊). Il y a, par ailleurs, des notions que je n’avais jamais creusées avant cet article. Afin d’introduire les deux articles en même temps, je vais schématiser l’ensemble des chapitres sur cette partie.
Tout d’abord, l’idée est de récupérer un maximum d’informations sur l’infrastructure sur laquelle nous allons effectuer nos tests afin de vérifier que les composants physiques ont bien été associés entre eux lors de l’achat du matériel, et s’ils ont été bien configurés.
Vérification de l’infrastructure, et de l’OS :
- Vérification des débits maximums que peut supporter chaque composant :
- RAM
- Network
- Storage
- Vérification de la version du firmware de la carte réseau
- Vérification de la MTU du DVS
- Vérification des releases notes & des known issues du build du vSphere
Une fois que toutes les vérifications côté infrastructure auront été faites, il faudra vérifier les configurations côté OS :
- Vérification de la MTU de la carte réseau
- Vérification du débit maximum de la carte réseau
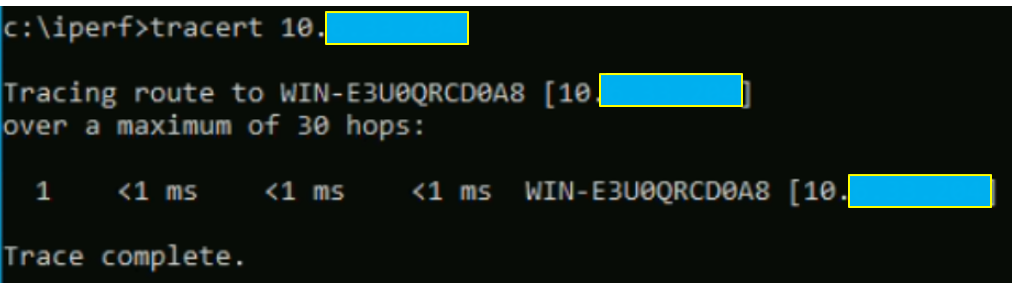
- Vérification du nombre de sauts entre la VM1 et la VM2
Spécification des serveurs avec leurs débits maximums :
2X Intel E810-XXV for SFP 25 Gbps (icen driver) = 3,125 GB/s
8X DDR4 LRDIMM 3200MT/s = 25,6 GB/s
4X Disque AG 1,6 To Enterprise NVMe U.2 Gen4 SATA 6Gbit/s (MTFDDAV480TDS) = 0,75 GB/s
12X Disque 3,84To SSD SAS ISE Lecture intensive 12Gbit/s (MZILT3T8HBLS0D3)= 1,5 GB/s
N.B : les outils comme « iperf » travaillent avec des « gigabytes » tandis que les OS type Windows travaillent quant à eux avec des « gigabits ».
Vérification des cartes réseau présentes sur l’ESXi
Le point de départ de tous les tests que nous allons effectuer sera de récupérer la liste des cartes réseau, et trouver celle qui nous intéresse en fonction du PortGroup ou du Segment NSX.
La commande pour récupérer la liste des cartes réseau est :
esxcfg-nics -l 
Dans notre cas, c’est la « vmnic2 » qui nous intéresse car c’est elle qui porte les workloads de tests que nous allons créer par la suite (et c’est aussi celle qui nous pose problème).
Afin de lister la version qu’utilise cette vmnic, il faut taper la commande
esxcli network nic get -n vmnic2 Comme vous pouvez le voir, elle utilise un driver de type « icen » en version 1.6.2.0
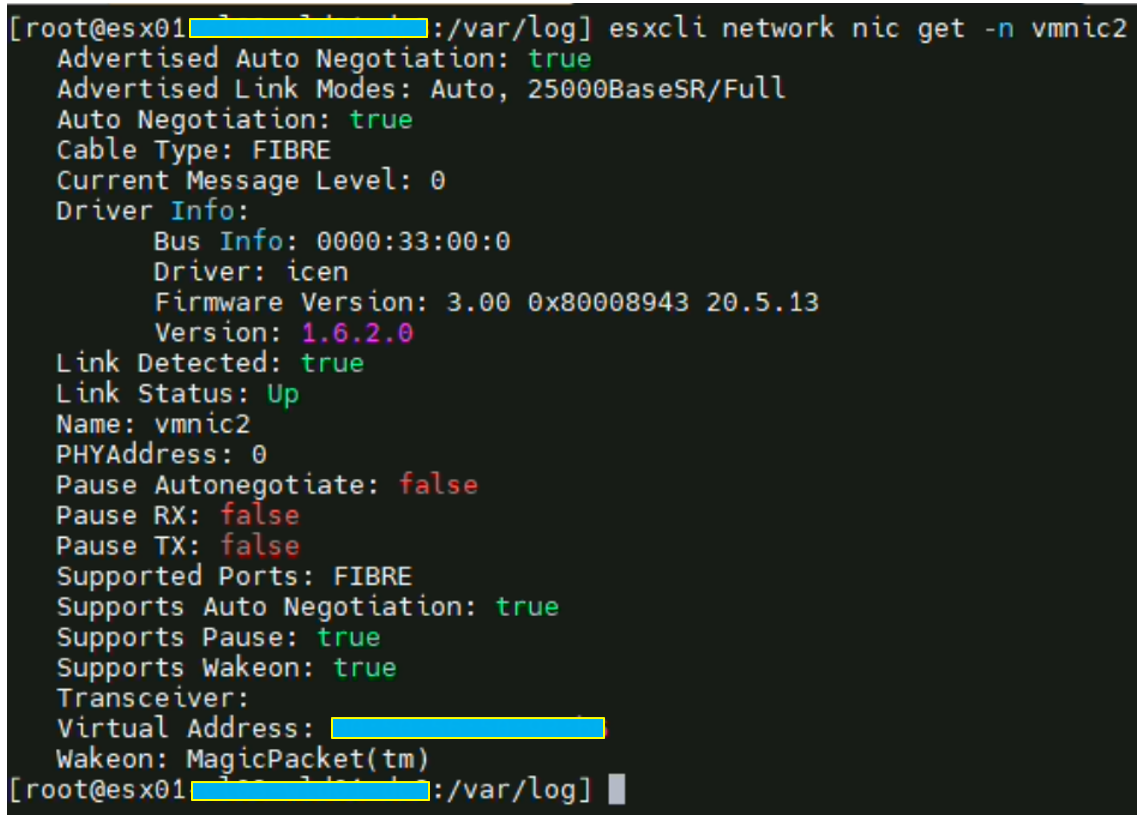
Mon serveur ayant été déployé à travers une stack VCF, le firmware est forcément compatible avec la HCL VMware (Hardware Compatibility Guide). Cependant, si ce n’est pas votre cas, vous devez chercher votre carte et tomber sur une page de ce type. C’est également utile pour vérifier les firmwares disponibles des cartes.

Dans mon cas, la version 1.12.5.0 est ressortie mais elle n’a malheureusement aucune notation sur les releases notes en ce qui concerne une potentielle amélioration de performances sur les technologies telles que le RSS, LRO,…
CG VMware driver 1.12.5.0

Vérification des known issues du build de la version vCenter 7.0.3 21477706 (3Ul) :
Étant donné que l’infrastructure a été déployée à travers du VCF on VxRail, il y a peu de chances que les releases notes indiquent un quelconque problème de performance sur du VXLAN. A tout hasards je suis quand même allé vérifier.
Il y a deux issues qui ressortent mais qui ne correspondent pas totalement à mon cas. Par acquis de conscience, j’ai quand même testé les workaround… sans effet.


Vérification des known issues du build de la version ESXi 7.0.3 20328353 (3Ug) :
Aucune known issue sur un quelconque problème de performance sur des cartes broadcom
Network:
Vérification de la MTU du DVS :
Sur cette partie, rien de plus simple. Il faut vérifier que le DVS est bien configuré avec une MTU de 9000
N.B : l’ensemble de la chaine doit pouvoir gérer les Jumbo Frames, c’est très probablement le cas dans une infrastructure VCF mais ça l’est moins dans une infrastructure legacy. Il faut donc le vérifier quand même.
Networking > Select DVS > Edit Settings
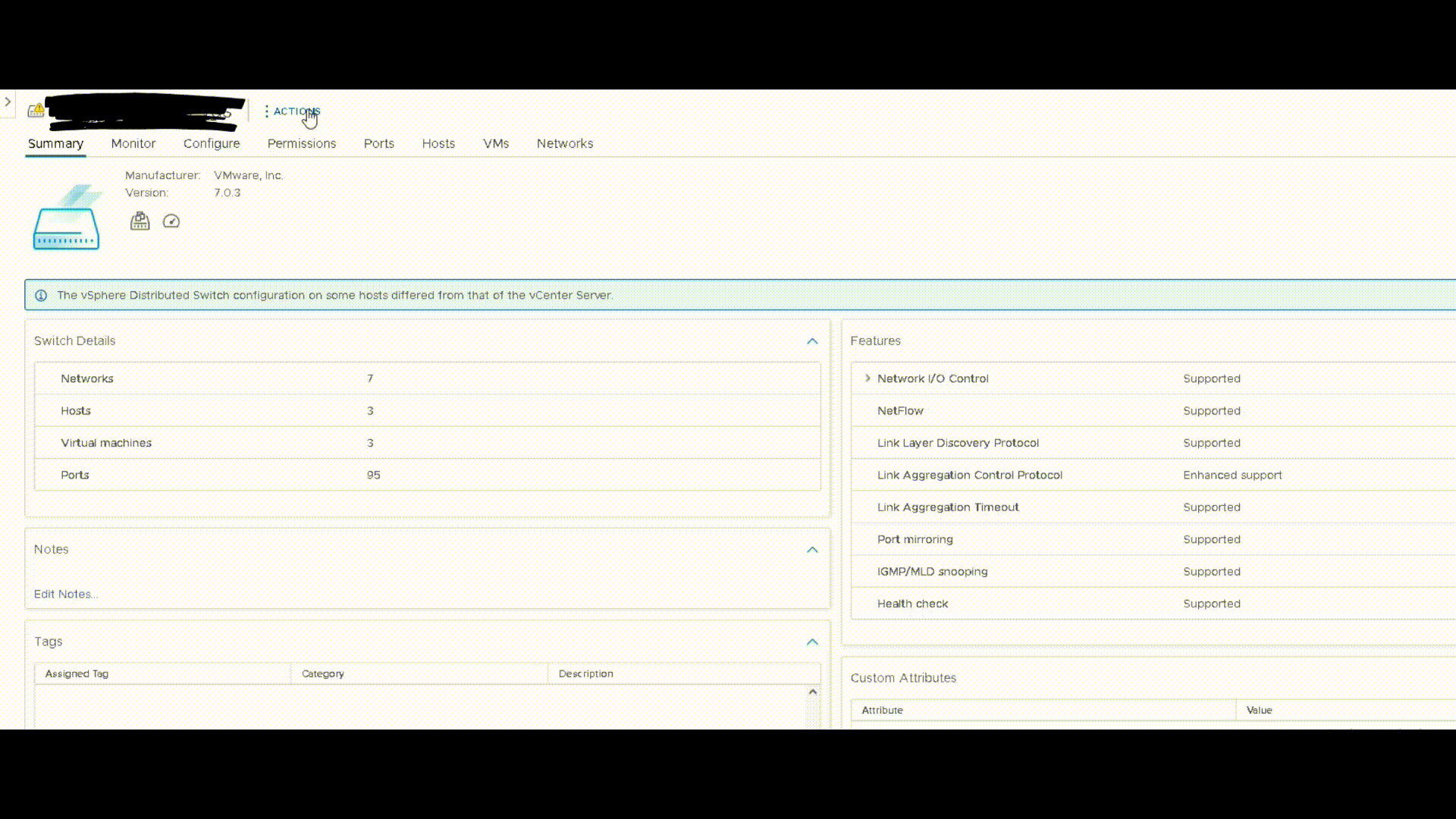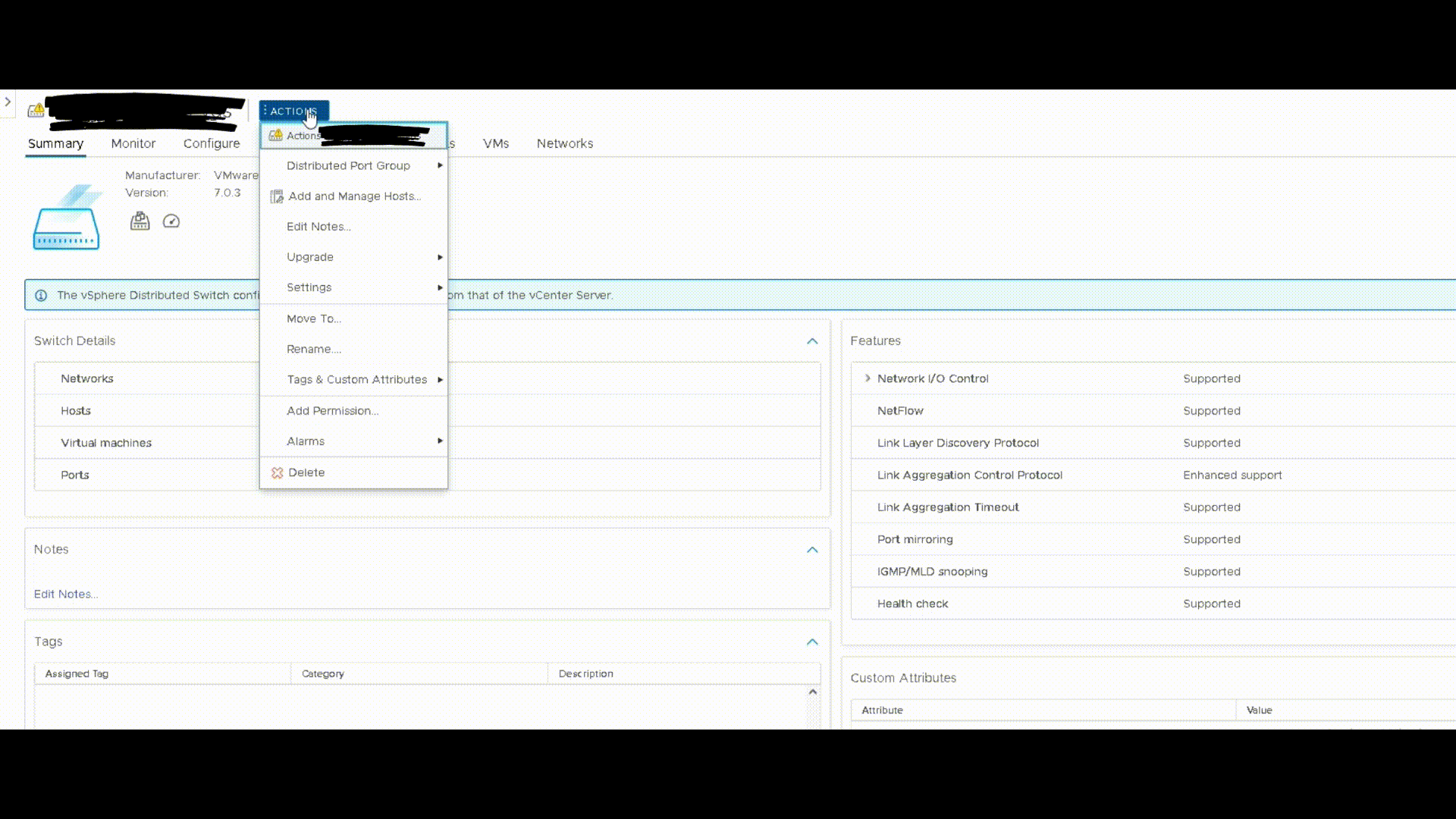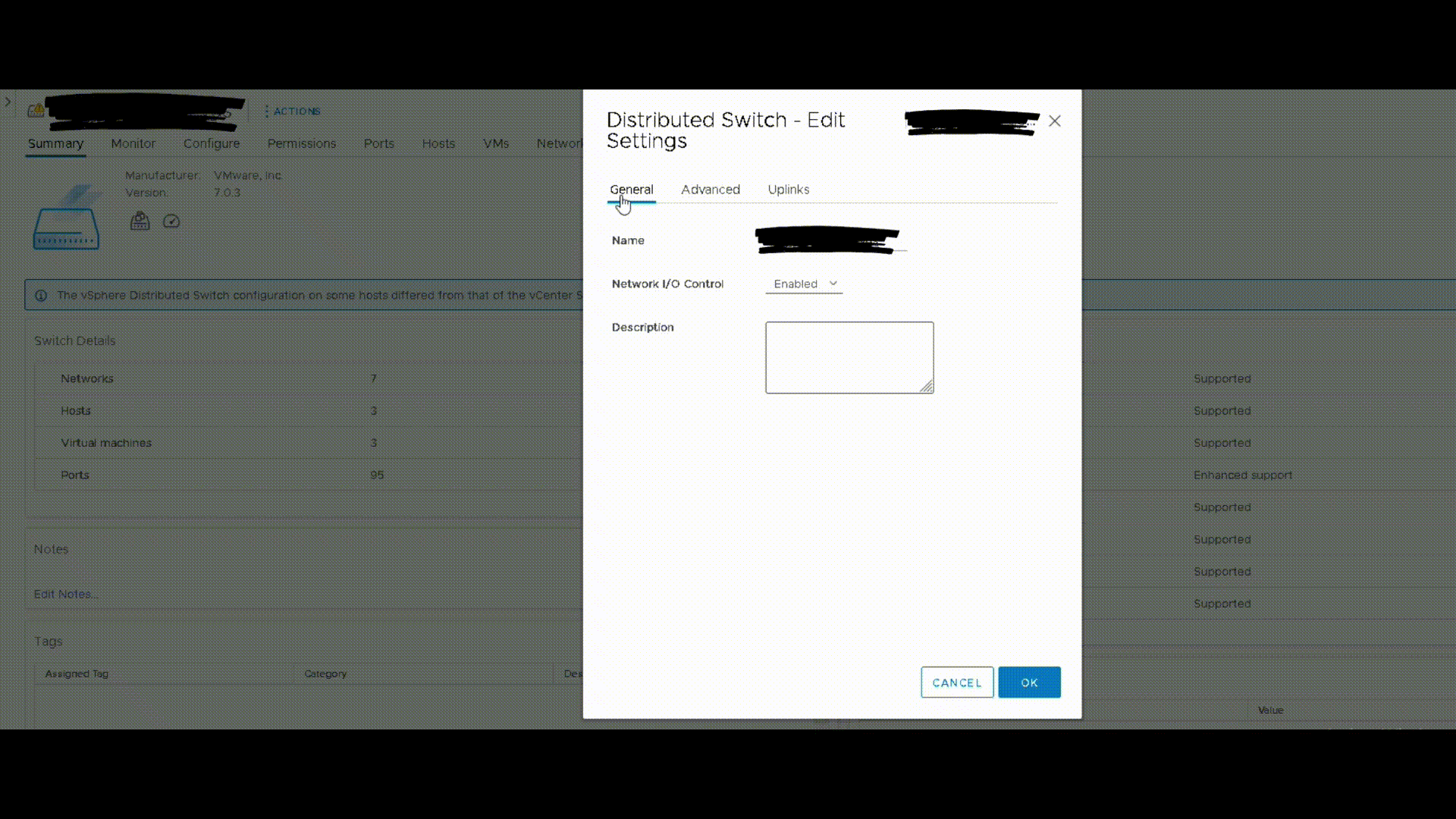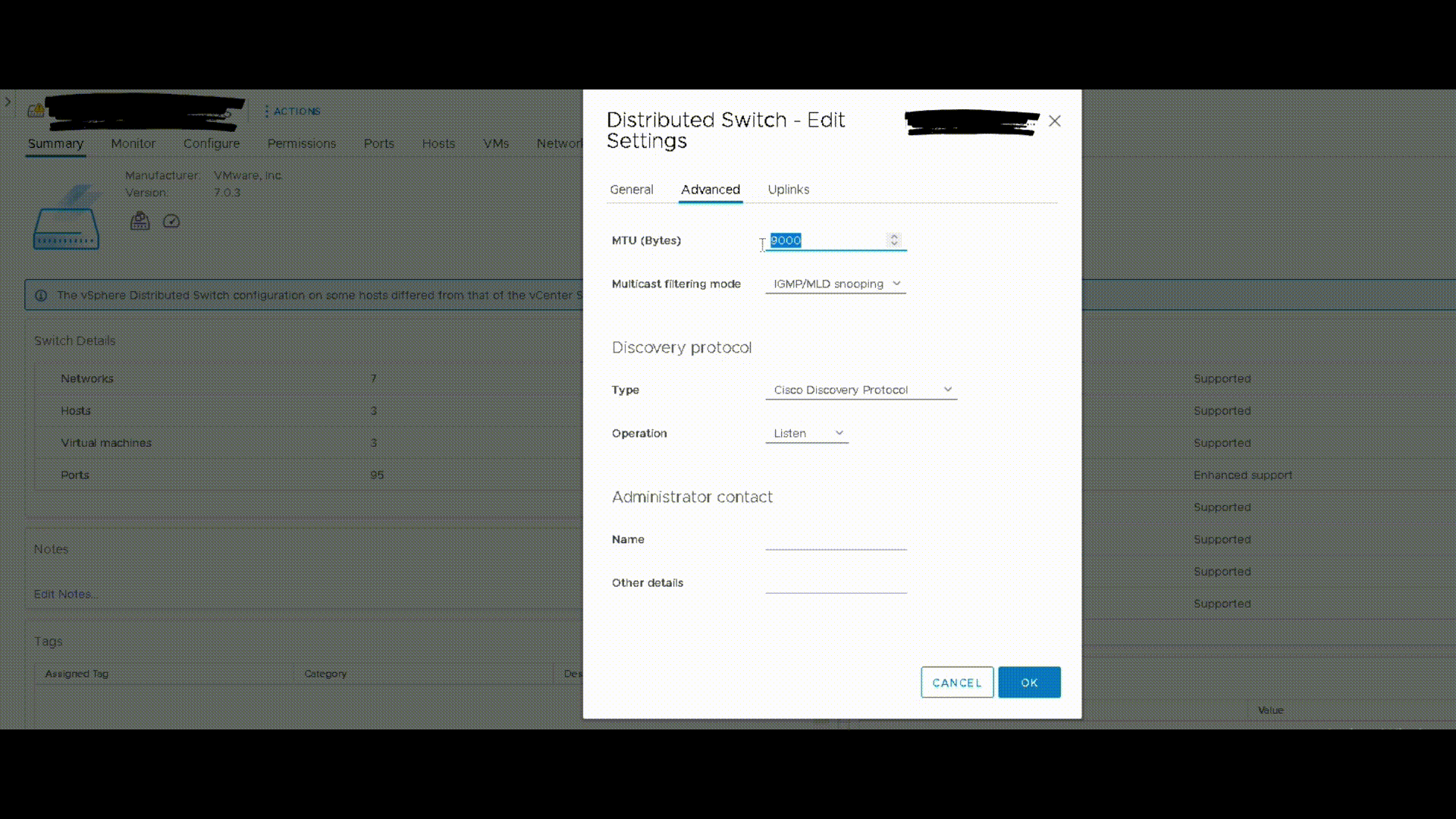
Validation du MTU à 8972
Recommandation VMware https://kb.vmware.com/s/article/1003728
Etant donné que nous avons pu valider le MTU au chapitre précédent, nous pouvons maintenant valider son bon fonctionnement via un « vmkping » entre deux ESXi.
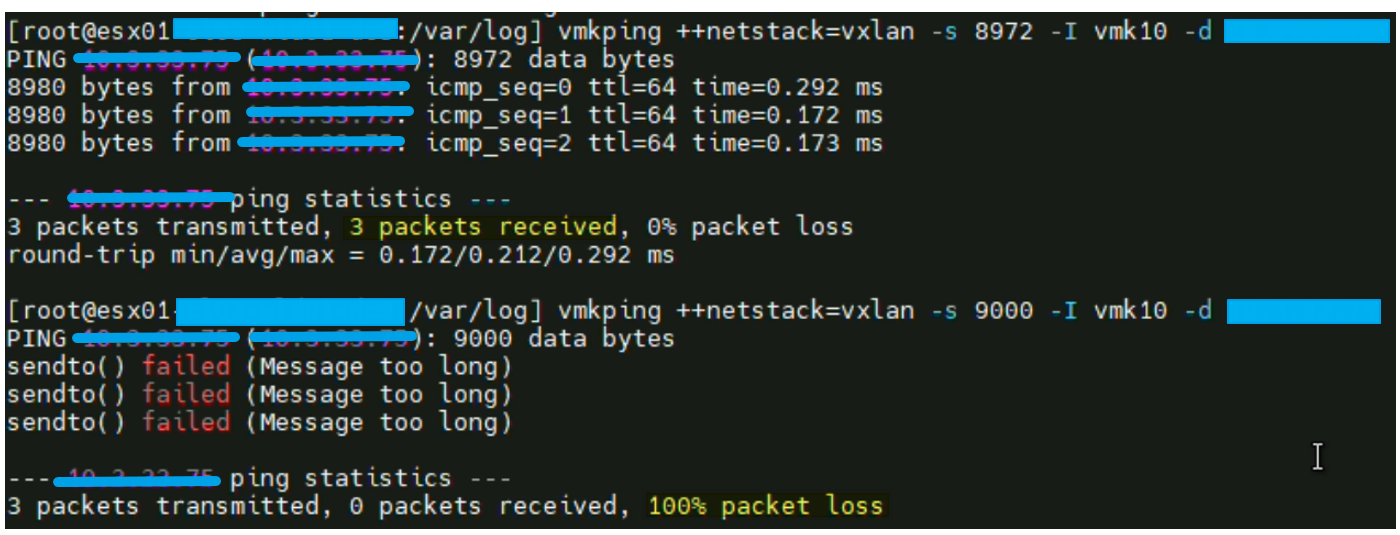
Test validé avec succès.
Nous pouvons donc passer au vif du sujet avec la création de 2 VMs de test sur le vCenter, ainsi que la création d’un PortGroup dédié pour vérifier les performances côté legacy.
Il est à noter qu’idéalement, ce type de tests doit s’effectuer en période creuse sur l’infrastructure. C’est d’autant plus vrai lorsqu’elle est soumise à des variations de charge au niveau des workloads.
N.B : Les machines utilisées sont des Windows Serveur 2019 Build 1809 mais le processus est identique si vous avez des machines Linux.
Dans un premier temp, nous allons vérifier qu’il n’y a pas d’équipements intermédiaires entre les deux VMs afin d’éliminer le maximum de problèmes qui pourraient être liés à un FW par exemple.
Vérification des performances de la carte réseau vmxnet3 :
Étant donné que la carte réseau vmxnet3 indique une vitesse de 10Go sous Windows (probablement la même chose sur une Linux), nous devons vérifier que nous ne sommes pas bloqués par cette carte. Cette valeur est censée être purement visuelle, mais je n’ai pas trouvé de documentation officielle qui parle de cette valeur.
Pour le vérifier, il faut effectuer un test de loopback.
Pour ce faire, ouvrir un CMD avec « iperf3 -s », puis ouvrir un second CMD avec l’adresse IP (IP configurée sur la carte réseau qui pointe sur le PortGroup ou Segment. Vous pouvez aussi directement le faire sur l’adresse loopback) de la carte réseau.
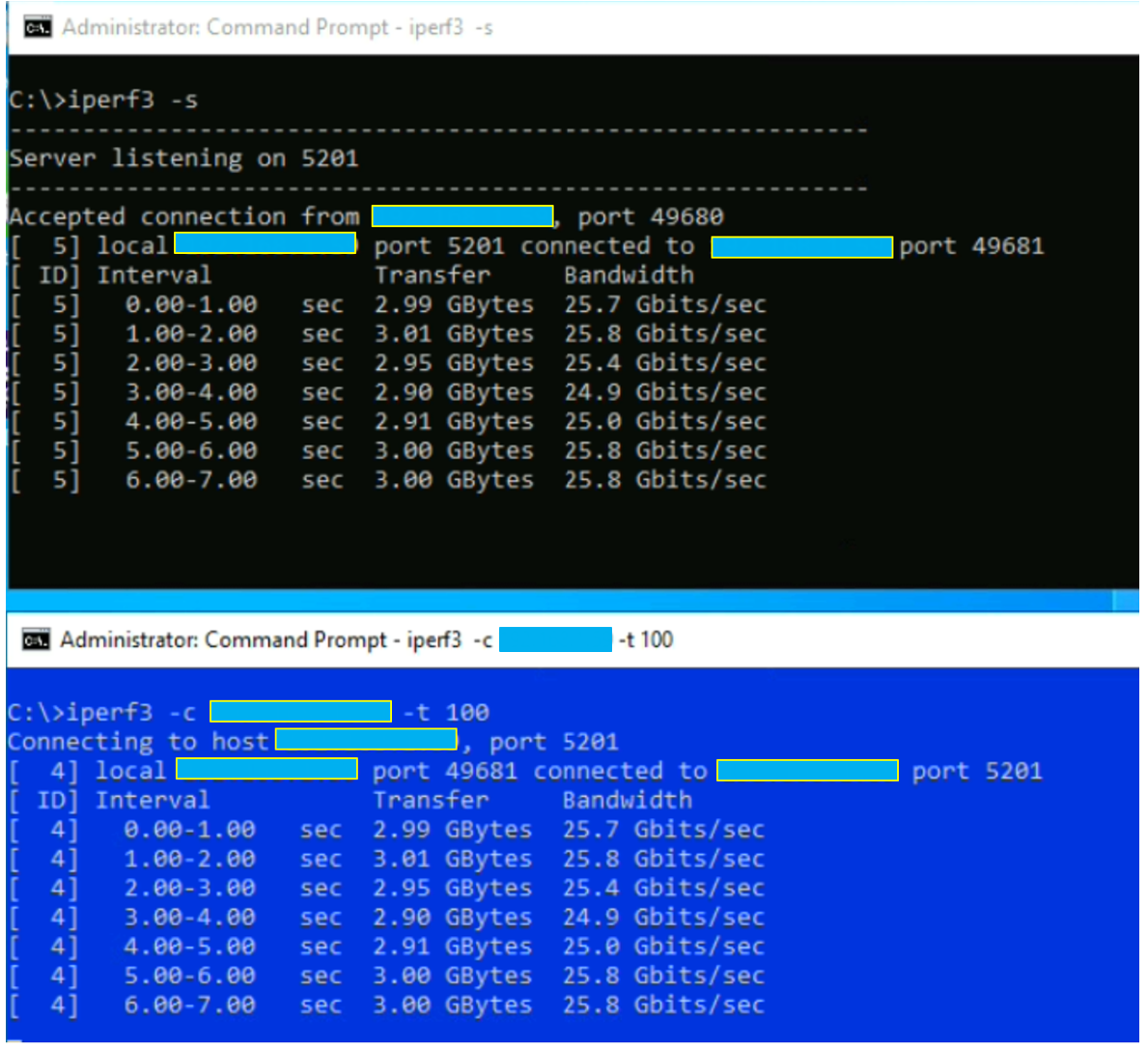
Nous obtenons bien les 25Gbits/s que la carte physique peut délivrer.
En noir, le CMD iperf3 serveur
En bleu, le CMD iperf3 client
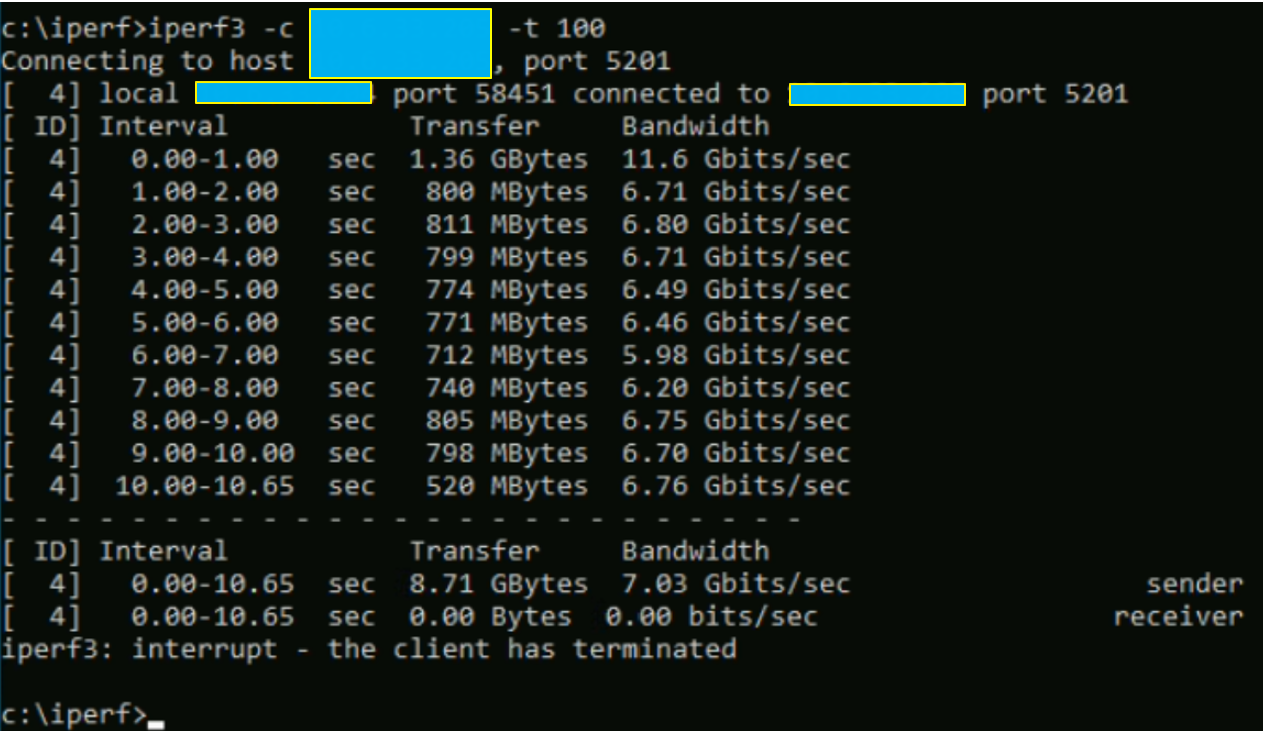
Cette fois-ci, nous sommes prêts à vérifier les performances réelles des VMs en mode iperf3 sur deux ESXi différents mais appartenant au même rack pour encore une fois supprimer toute éventualité d’un équipement intermédiaire qui poserait problème.
Pour cela, il faut lancer iperf3 en mode serveur (iperf3 -s) sur la machine « test-kevin-bp-limit1 », et le lancer en mode client sur la machine « test-kevin-bp-limit-2 ».
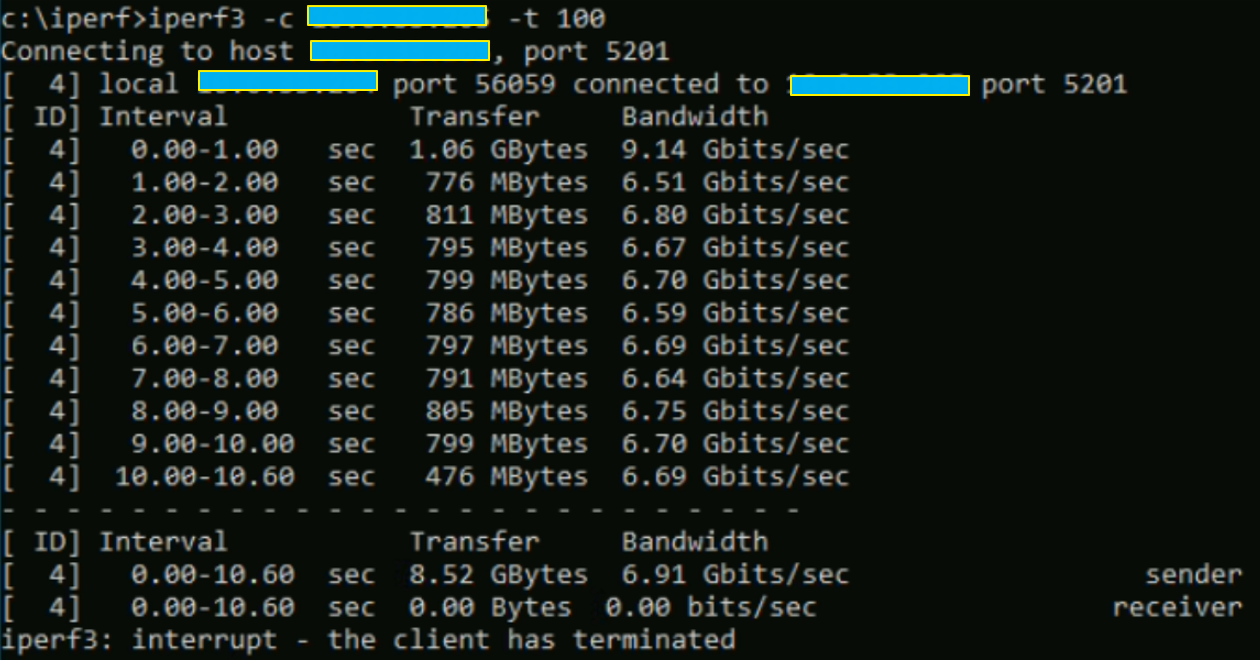
Comme vous pouvez le voir, les valeurs sont très largement en dessous de ce que peuvent supporter les cartes réseau physiques et virtuelles.
Prochain test.
Nous recommençons le même test mais en basculant les deux VMs sur le même ESXi.
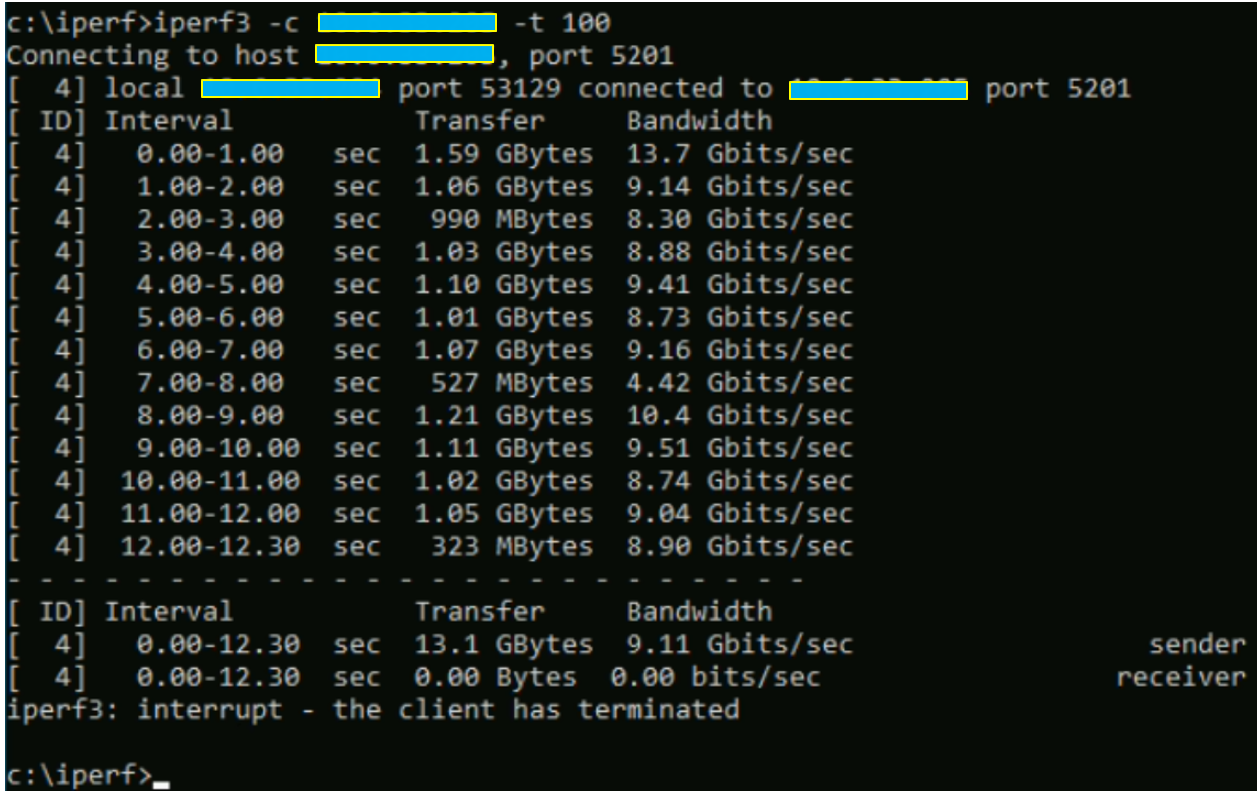
Cette fois-ci, les performances sont un peu mieux mais elles restent toujours très en dessous des valeurs max possibles ( ~185% de perfs manquantes).
Validation des debits : ESX01 vers ESX02 via vmk2
Depuis maintenant plusieurs versions vSphere (au moins depuis la version 6.5 U2 d’après William) il est possible d’utiliser iPerf3 sans même avoir besoin de le télécharger depuis une VIB. Il est nativement présent sur « /usr/lib/vmware/vsan/bin/iperf3 »
N.B : Si une erreur « bind failed: Operation not permitted » apparaît en mode serveur il suffit simplement de renommer le fichier iperf3 en iperf3.copy par exemple puis de le relancer.
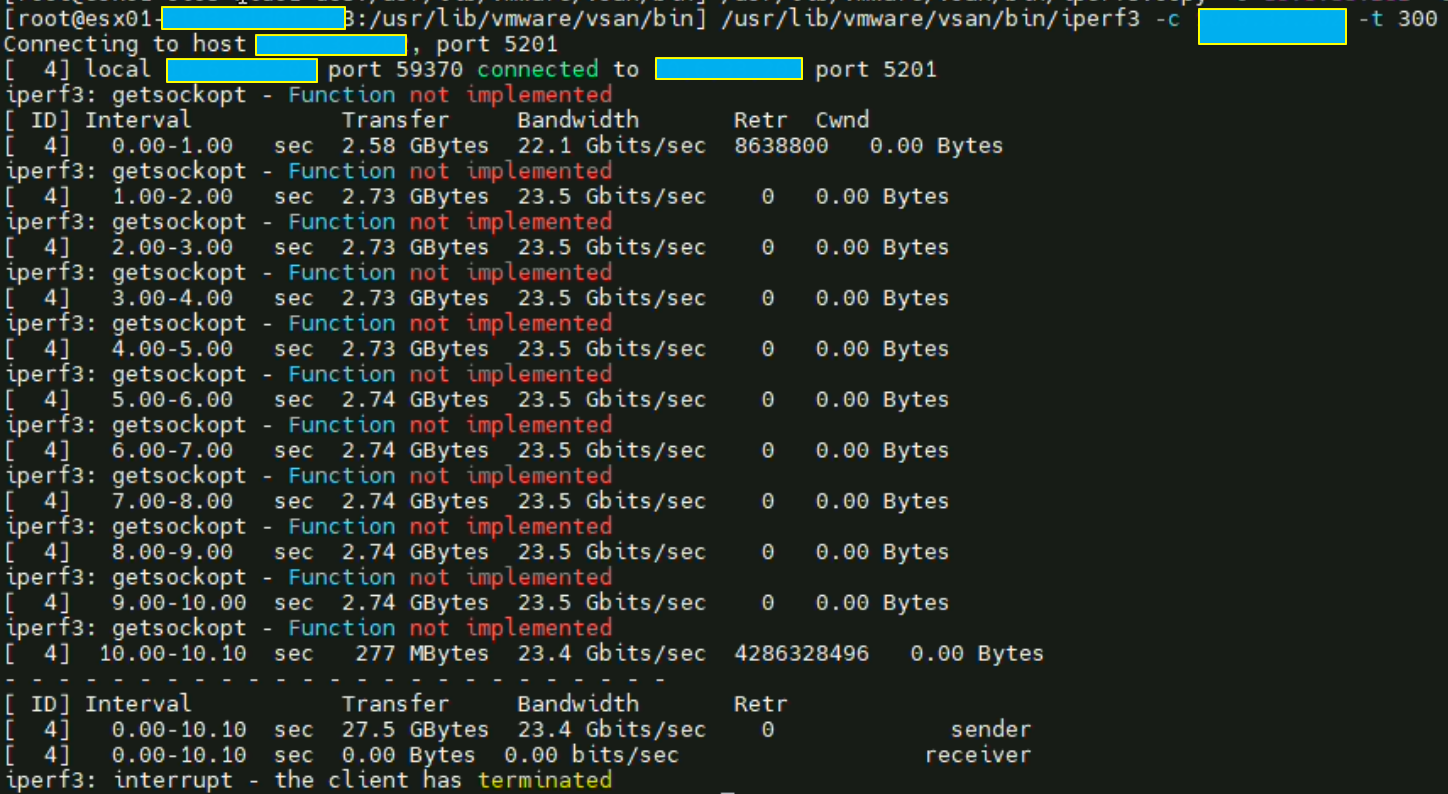
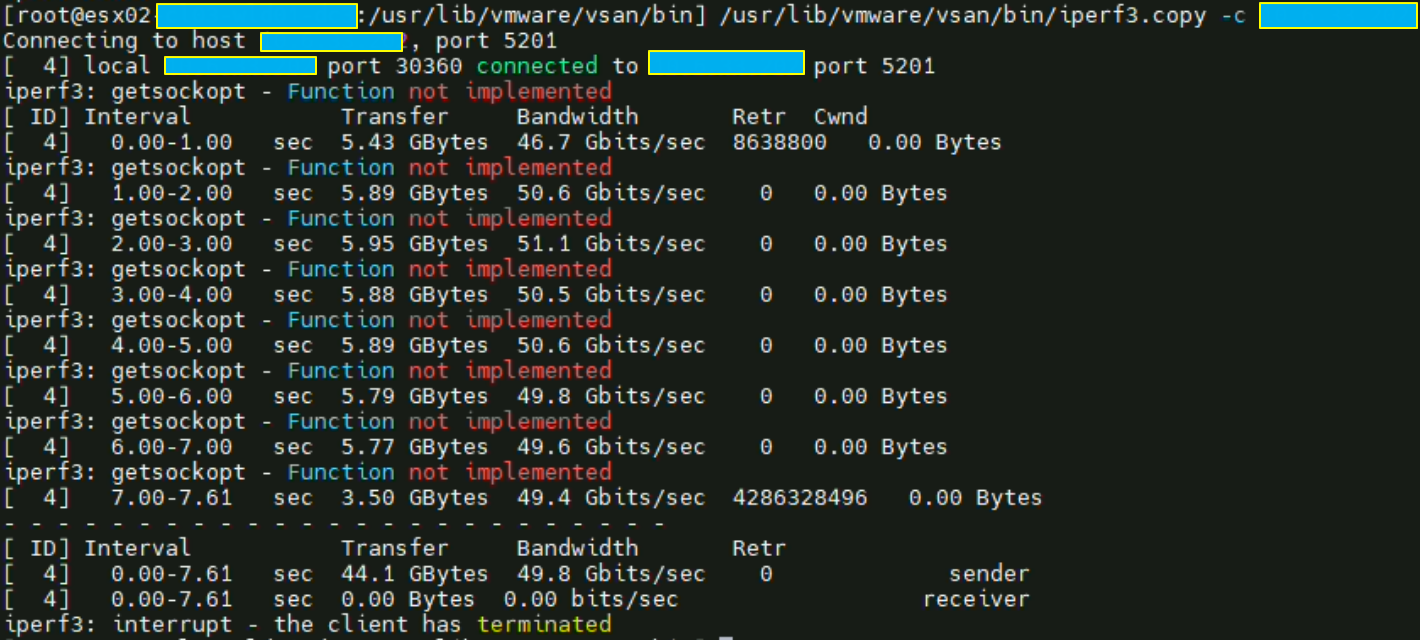
Même ESXi: test des debits en loopback
Ce test n’est là que pour valider les débits en loopback.
Les débits ne devraient jamais être en dessous de ce que peut faire la carte physique, dans notre cas il s’agit d’une 25 Gbit/s. Ici nous pouvons atteindre le double de cette valeur.
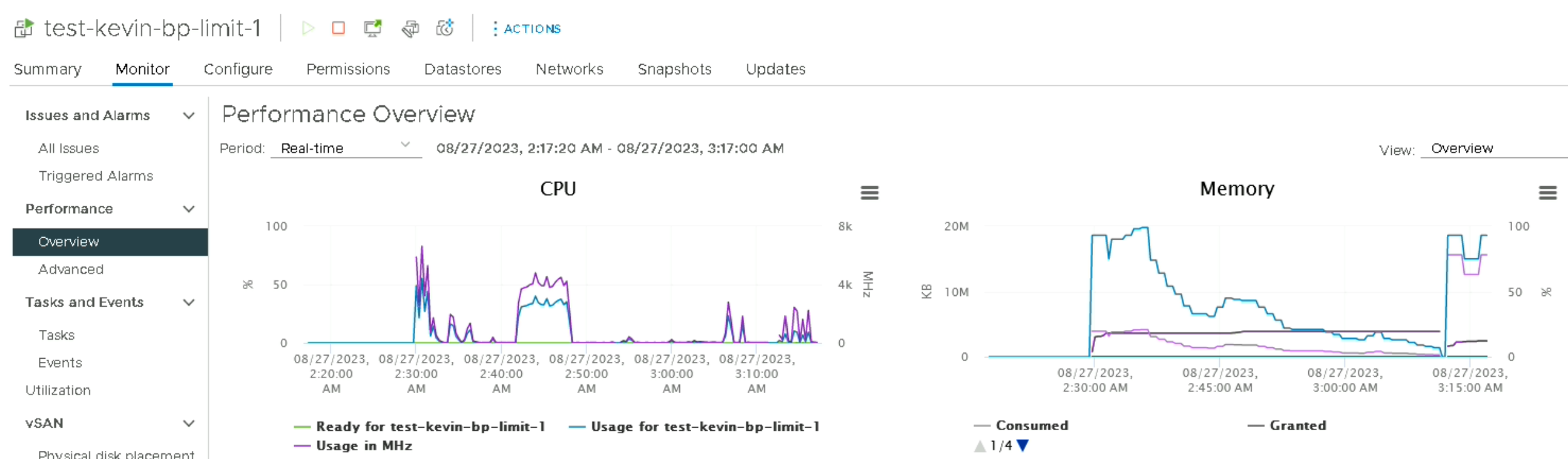
Bascule des VMs de 4vCPU/4GB RAM à 8vCPU/16GB RAM :
Les VMs ayant été configurées avec 4 vCPU et 4 GB RAM, nous pouvons les passer à 8 vCPU et 16 GB RAM. L’idée est de vérifier que les specs VMs n’influencent pas les performances réseau, ce qui pourrait être le cas notamment sur la partie NSX où les technologies comme le RSS / LRO dépendent directement du nombre de cœurs dont dispose(nt) la/les VM(s).
Même rack, ESXi différent.
Aucune augmentation des performances.
Les specs ne sont pas (ou plus) liées aux performances que peuvent fournir les VMs.
Aussi, globalement, les impacts de performances liés aux cœurs (vCPU) des VMs étaient réels il y a plusieurs années, lorsqu’il n’y avait pas de technologies aussi abouties sur les processeurs et sur les cartes réseau. Aujourd’hui la majorité des VMs et OS savent faire de l’offload.
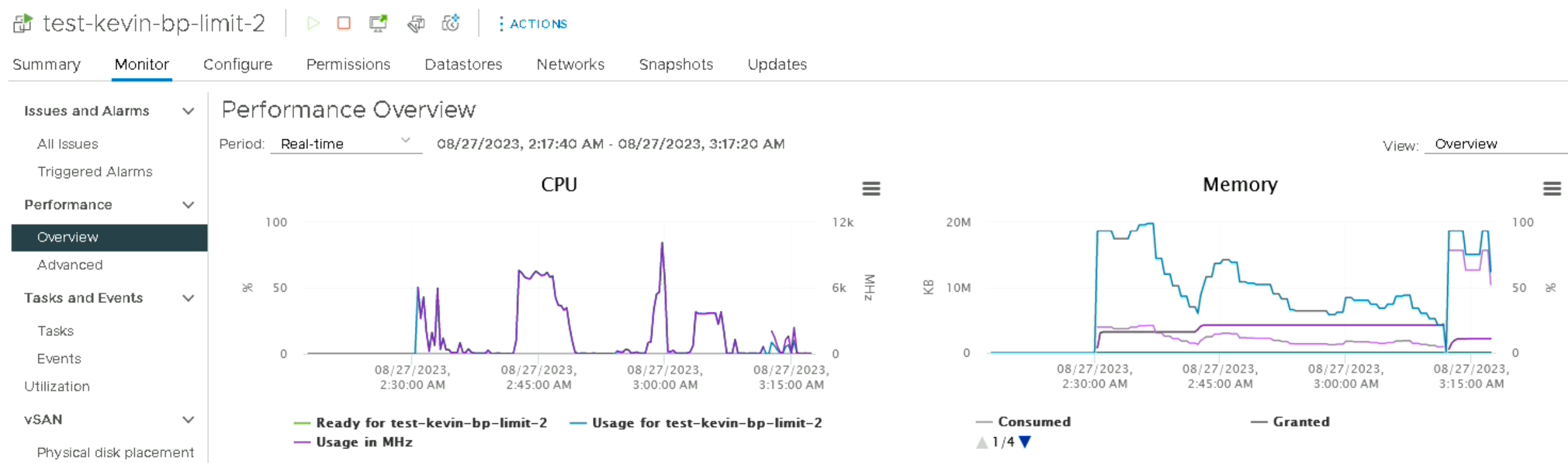
Corrélation des performances entre les 2 VMs
Un fait intéressant que j’ai remarqué pendant mes tests iPerf est que les deux VMs ont quasiment les mêmes graphiques de performance, surtout coté RAM où c’est flagrant.
vCloud Director, où commence l’overlay.
Cette fois-ci, nous allons importer ces mêmes VMs sur vCloud Director (vCD) afin de profiter des réseaux overlay qui y sont montés. Le test aurait pu être fait côté vCenter, mais il n’aurait pas représenté la réalité des workloads clients qui tournent sur vCD.
Même principe que pour les tests précédents, lancement d’un iperf3 sur la machine « test-kevin-bp-limit-1 » en mode client, et en mode serveur sur la seconde.
Même rack mais Transport Node différent
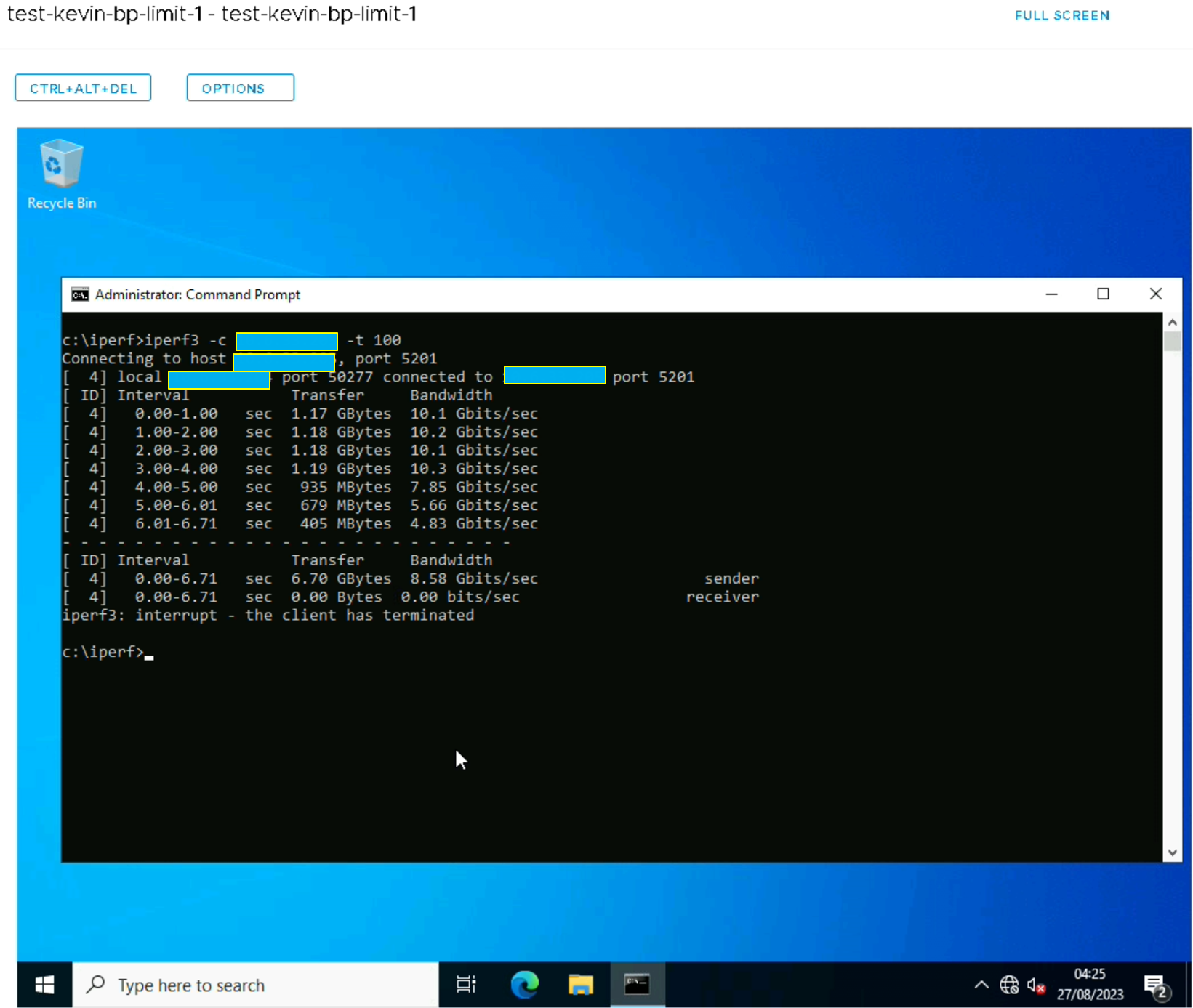
Etrangement, nous avons de meilleures performances qu’avec un réseau legacy. Dans le fond, cela reste assez incompréhensible étant donné qu’il y a une encapsulation des VXLAN sur un réseau overlay, mais l’idée reste de troubleshoot le problème donc nous mettons ces résultats de côté.
Second test, même rack et même Transport Node.
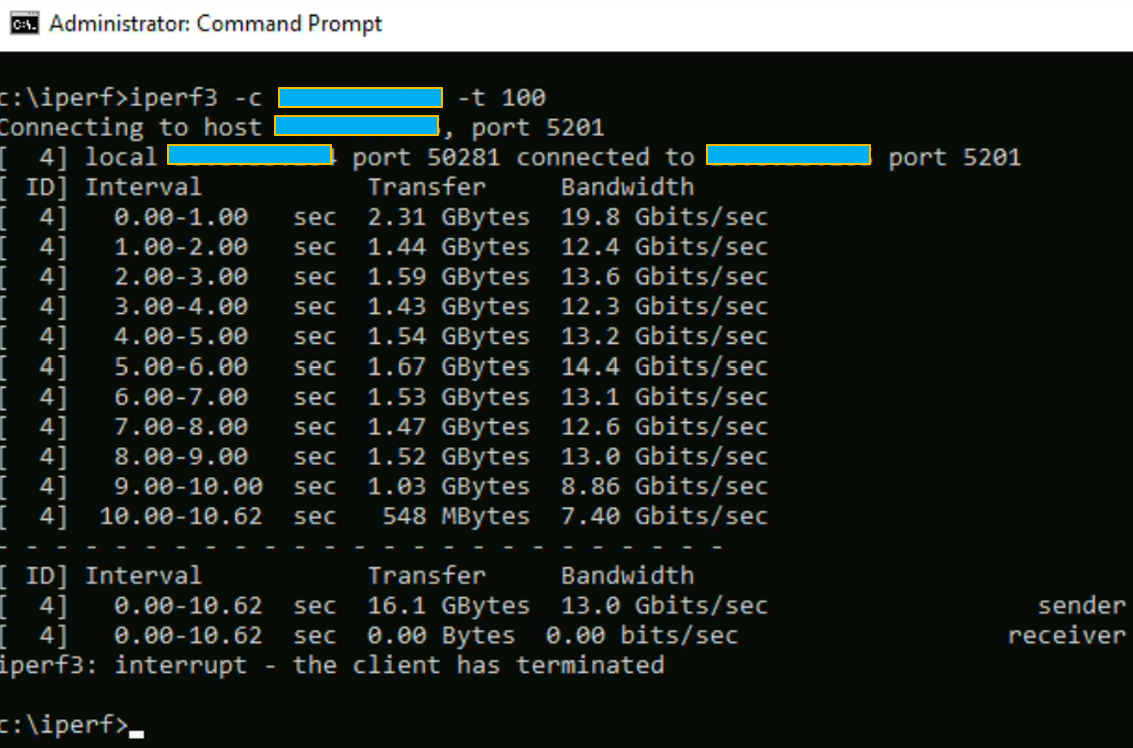
Encore de meilleures perfs.
Pour résumer, nous avons globalement de meilleures performances sur un réseau overlay en étant sur le même ESXi mais il faut encore aller chercher les Gbit/s manquants. Pour cela, il y a le « Live Traffic Analysis » sur NSX-T à partir de la version 3.1 qui nous permet de capturer le trafic entre 2 VMs afin de vérifier qu’il n’y a pas une feature qui pourrait réduire les performances.
Live Traffic Analysis
L’utilisation reste très basique. Comme « NetFlow », vous devez choisir les VMs, leur carte réseau puis le nombre de « Trace Sampling » et « Packet Capture Sampling ».
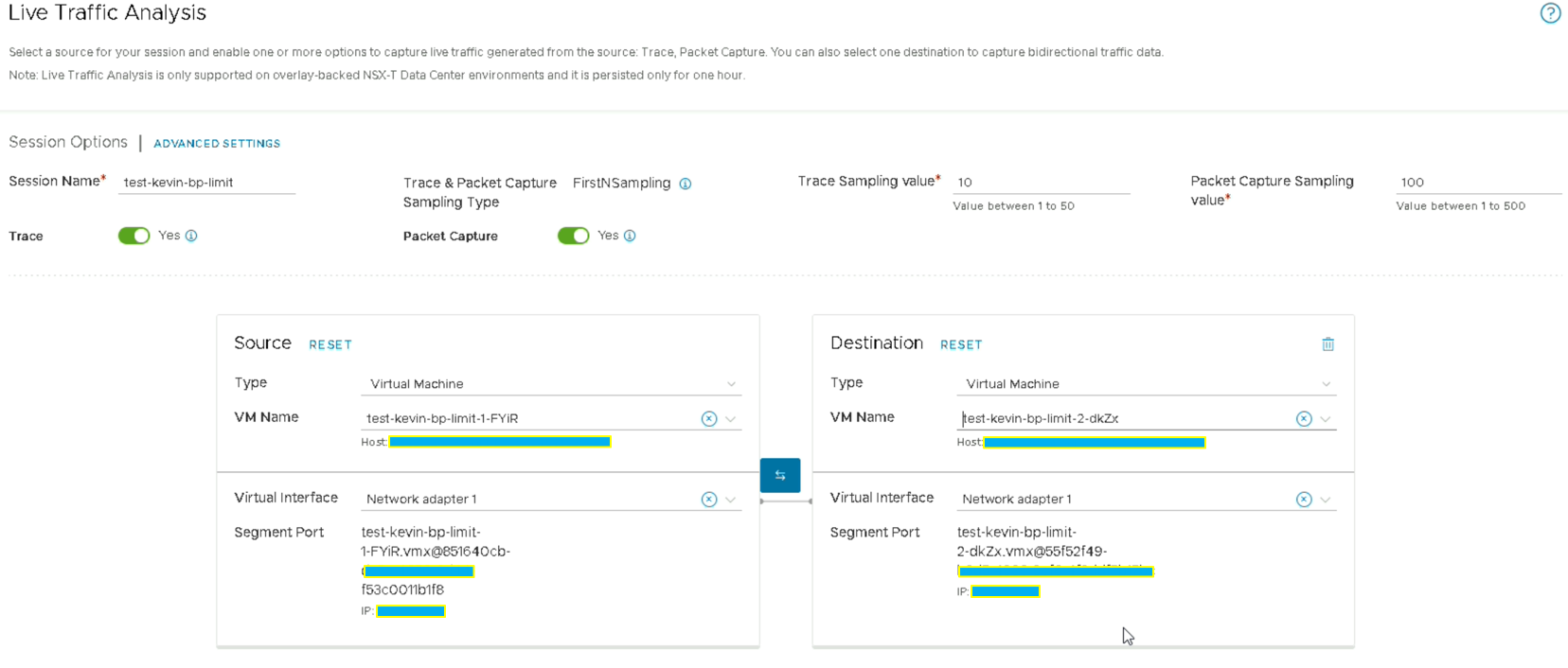
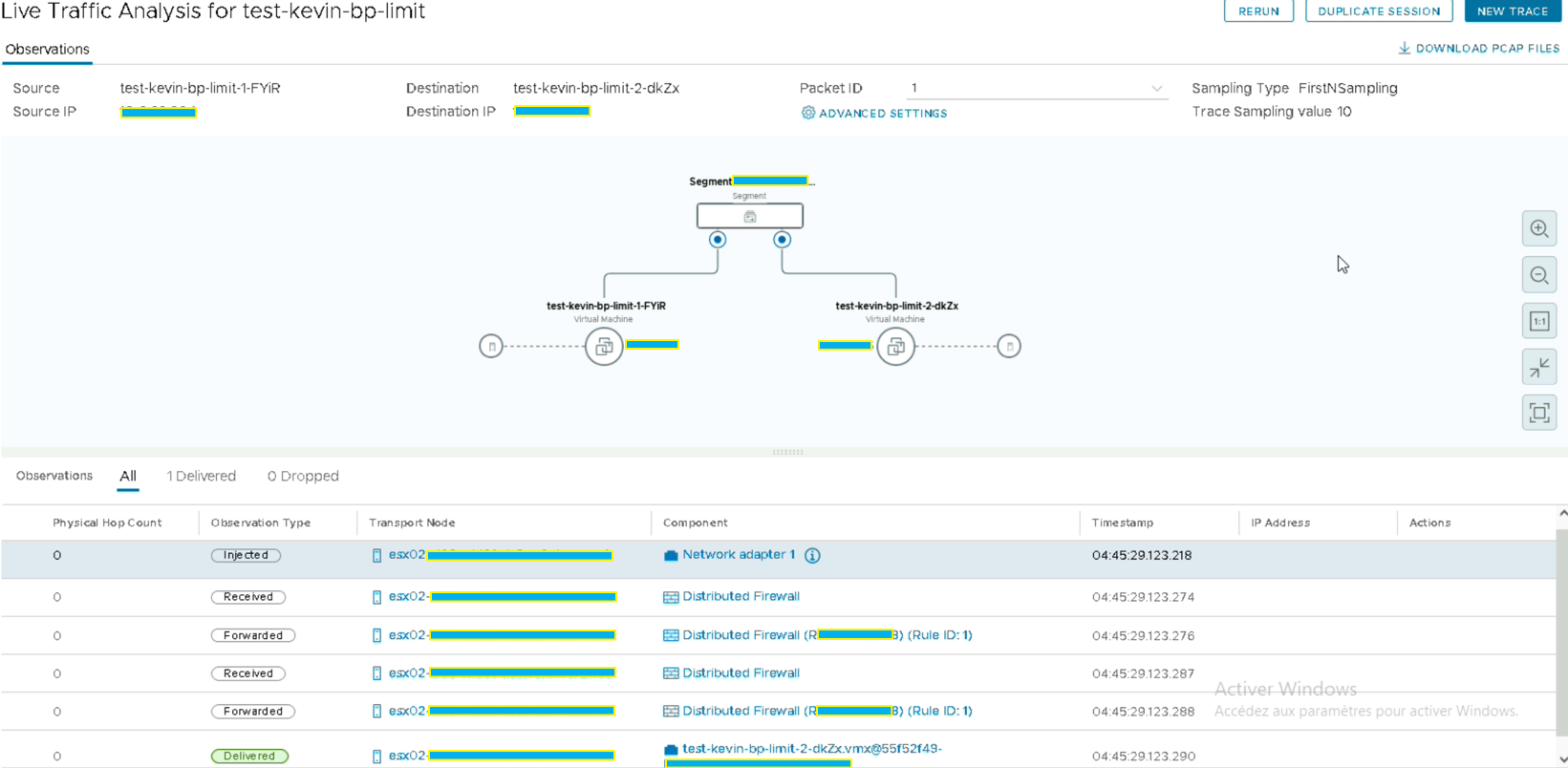
Ici, nous pouvons donc voir que les 2 VMs sont sur le même Transport Node mais qu’elles dépendent du DFW activé sur la stack.
C’est donc une piste qui est à privilégier car le DFW peut réduire les performances des VMs. Malheureusement, étant donné que ces Transport Node sont issus d’une infrastructure de PRODUCTION je ne peux pas le désactiver car la règle ID :1 est une règle généralisée sur toute l’infra. Cependant, je pourrai le vérifier je l’espère d’ici le prochain article lorsque j’aurai une PREPROD à disposition.
EDIT : Après vérification il s’avère que le DFW réduit les performances d’environ 1Gbit/s.
Transfert de fichier : Charge network de l’ESXi via « esxtop » :
Nous allons maintenant nous concentrer sur la charge que porte l’ESXi pendant un test de transfert de fichier. Pour ce faire, et comme dans le cas d’un réseau legacy il faut vérifier que la MTU est bien à 8900. Je vous épargne comment faire, je l’ai déjà détaillé au chapitre précédent.
Il faut donc simplement copier un fichier d’une taille suffisante (10 voire 50Go) de la VM « test-kevin-bp-limit-1 » vers la « test-kevin-bp-limit-2 » pour avoir le temps de vérifier du côté de « esxtop » le nombre de paquets transmis.
Une fois que les données sont récoltées nous allons effectuer ce même test mais cette fois-ci avec une MTU de 1514 afin de comparer le nombre de paquets transmis.
Pendant le test il faut ouvrir un SSH sur le Transport Node en question et vérifier ce qui s’y passe avec un « esxtop » en mode « n ».
Copie avec une MTU de 1514 :
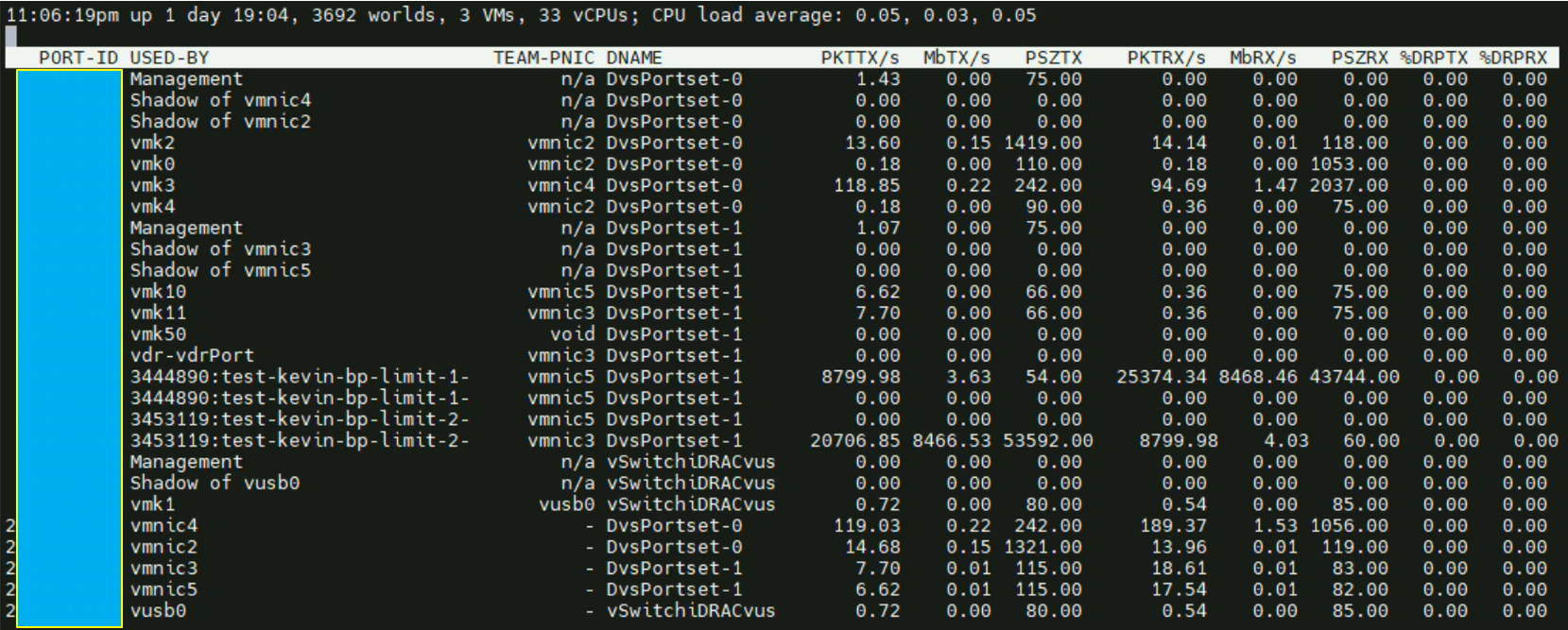
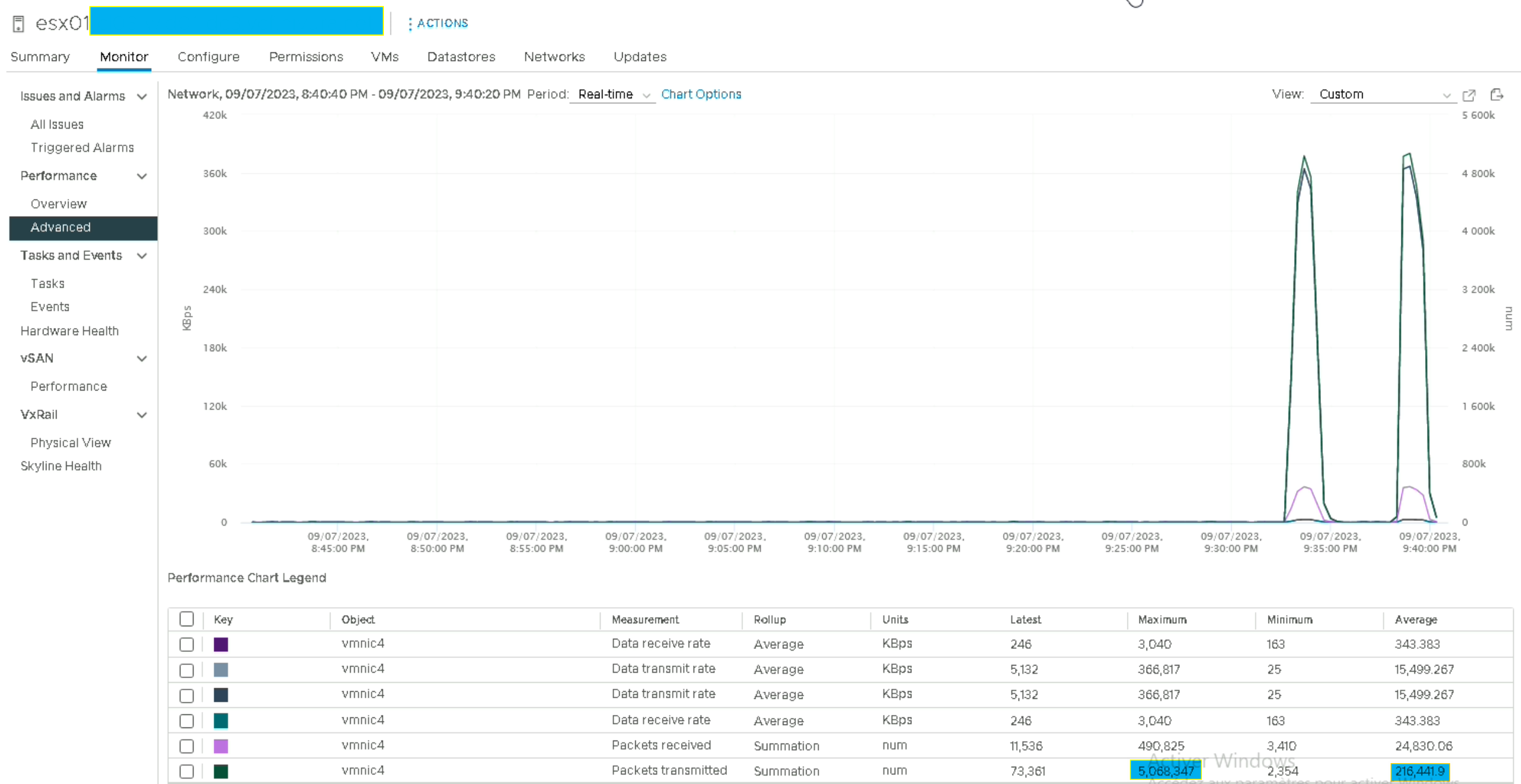
Ou on peut aussi le vérifier via le « Performance Charts » du vCenter
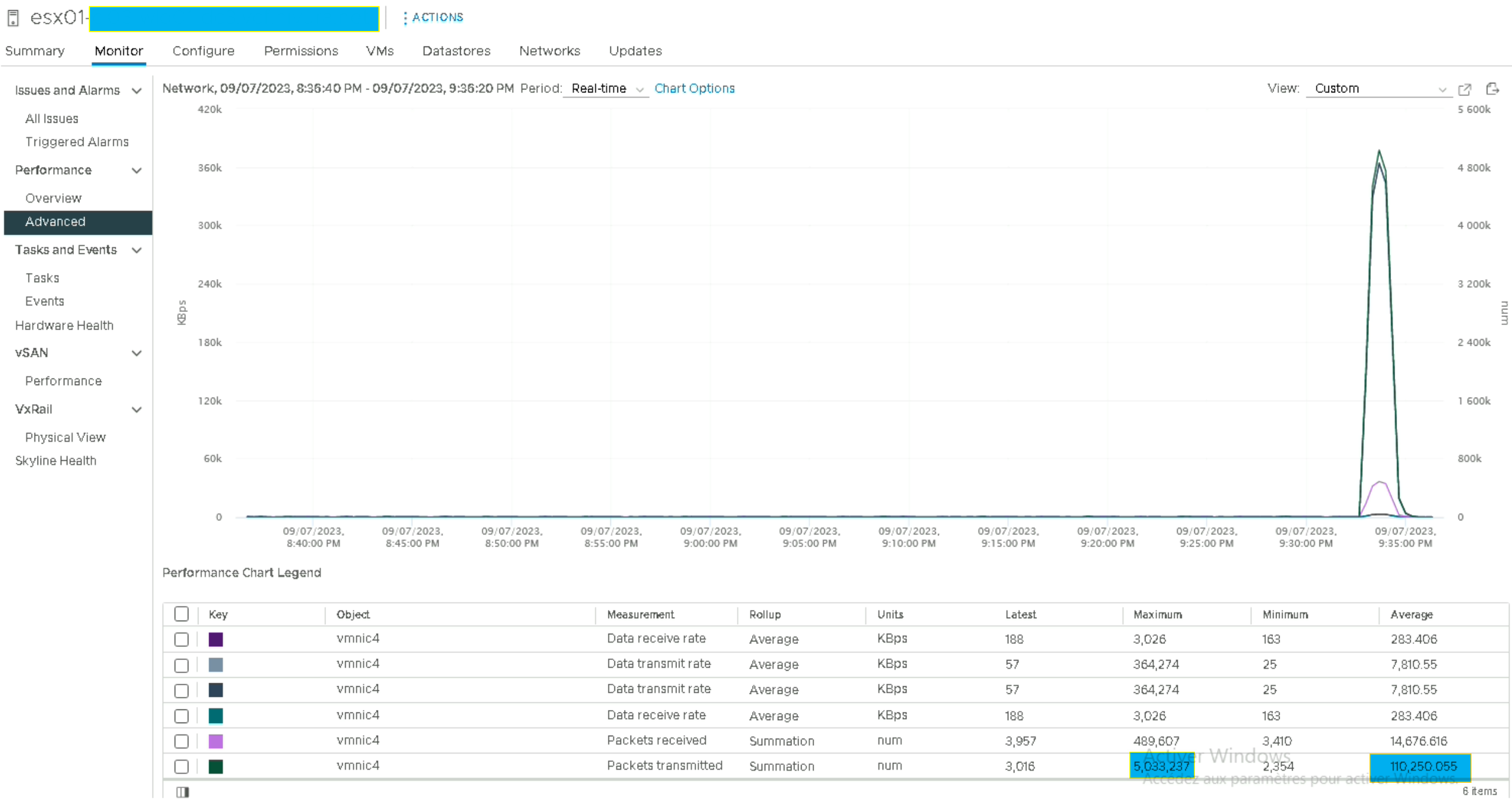
Nous voyons bien que la VM transmet jusqu’à 25k de paquets à la seconde tandis que la seconde VM n’en transmet que 9k (logique puisque c’est un fonctionnement en mode client-serveur).
Une fois les tests terminés le TN (et les VMs) devraient retourner en IDLE comme ci-dessous.
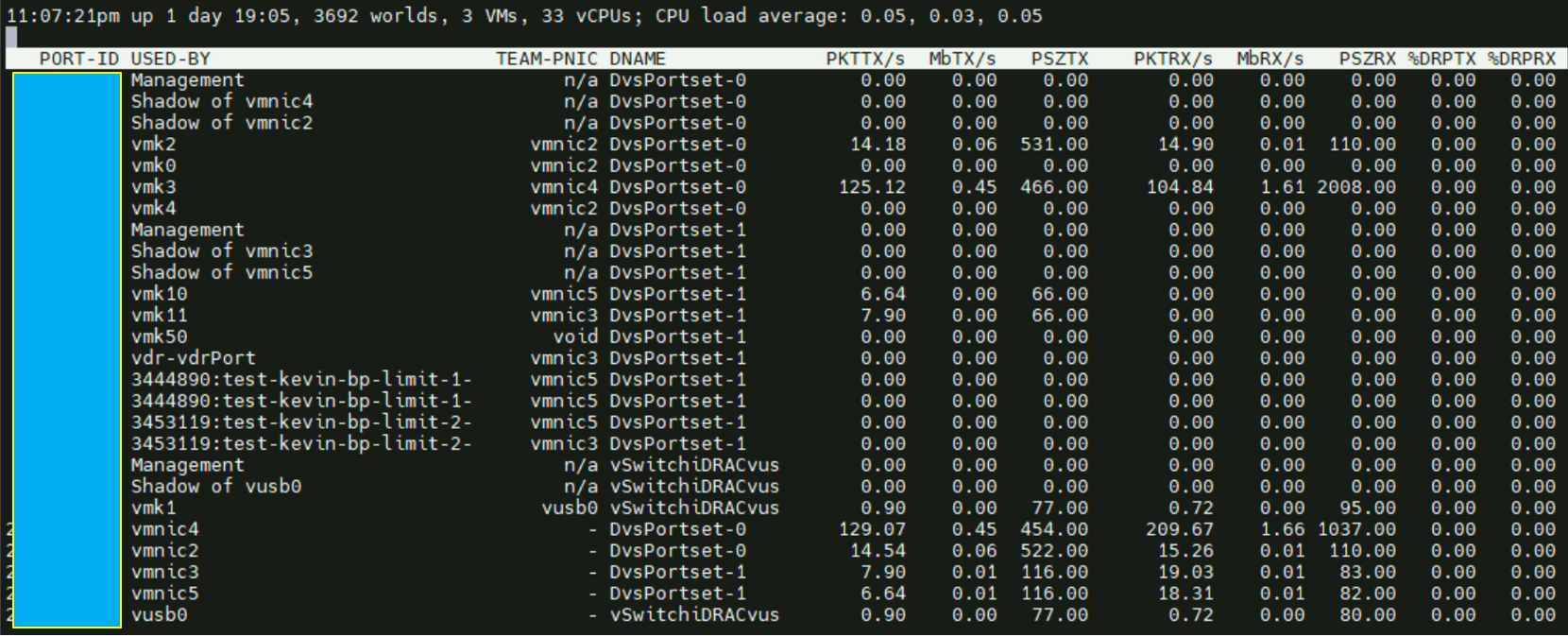
Cependant si nous repassons nos VMs avec des MTU de 1514 (non jumbo frames) les ESXi devraient afficher beaucoup plus de packets mais ce n’est pas le cas avec « esxtop », et sur le Performance Chart les valeurs maximales sont sensiblement les mêmes.
Copie avec une MTU de 8900 :
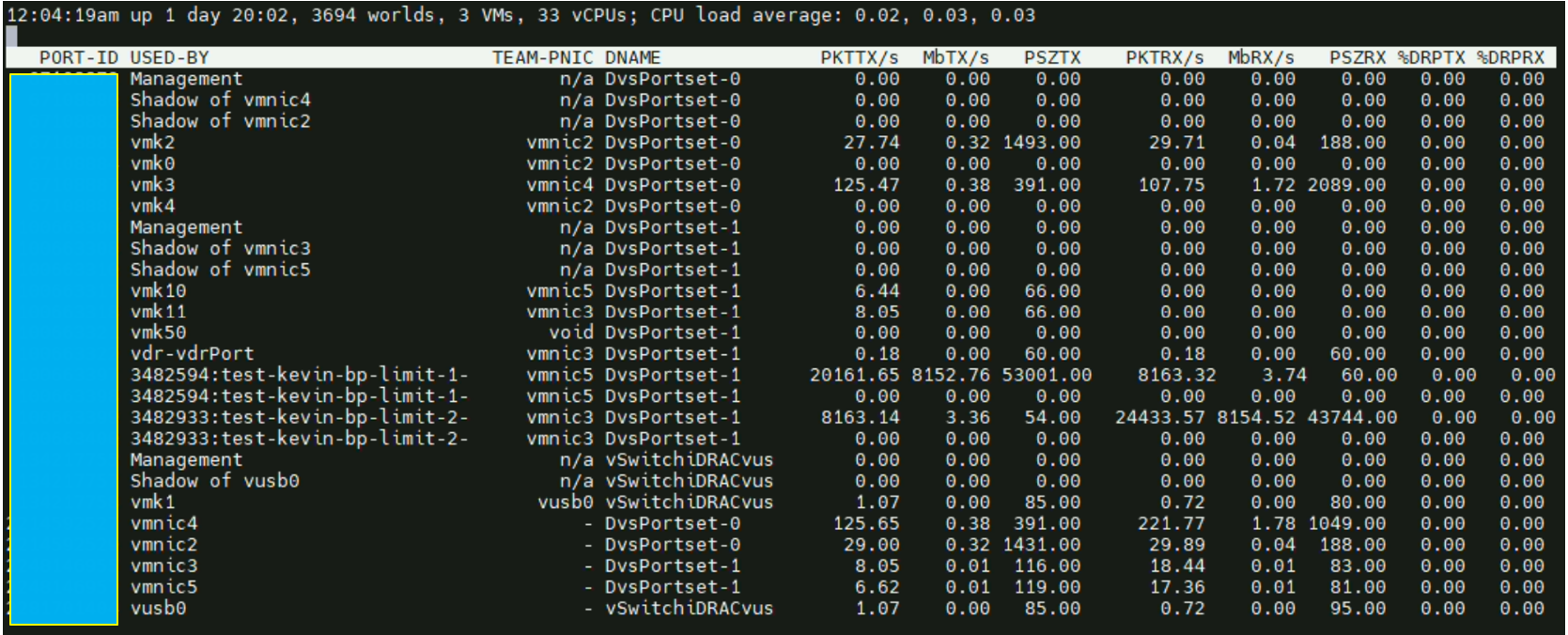
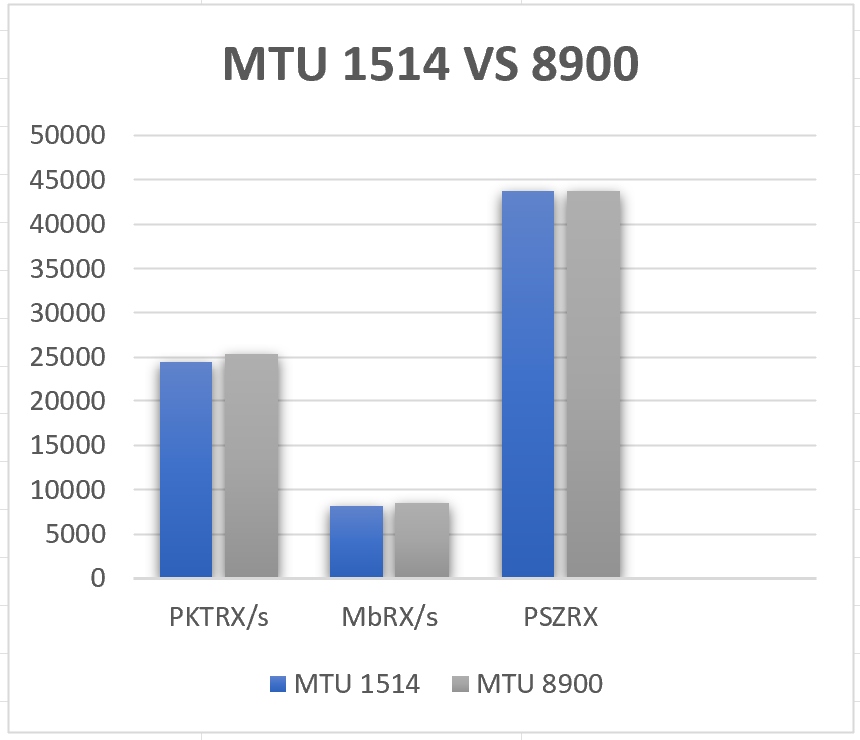
Dans un contexte logique, il devrait y avoir beaucoup plus de paquets transmis avec une MTU à 1514 plutôt qu’une MTU à 8900 parce qu’un paquet avec une MTU de 8900 contient en théorie jusqu’à 6 fois plus de données avec le même header VXLAN, il faut donc moins de packet pour le même volume de données.
Voir cet article très intéressant sur le sujet :
https://vswitchzero.com/2018/08/02/jumbo-frames-and-vxlan-performance/
Etant donné que les valeurs sont sensiblement les mêmes, il faut à minima vérifier que les paquets Jumbo fonctionnent réellement avec un simple ping contenant l’option « -l » pour la taille des packets et « f » ne pas fragmenter les packets s’ils dépassent la taille maximale.
N.B : Dans l’idée il faudrait aussi vérifier ce qui a transité d’une VM à une autre par un outil de type Wireshark.
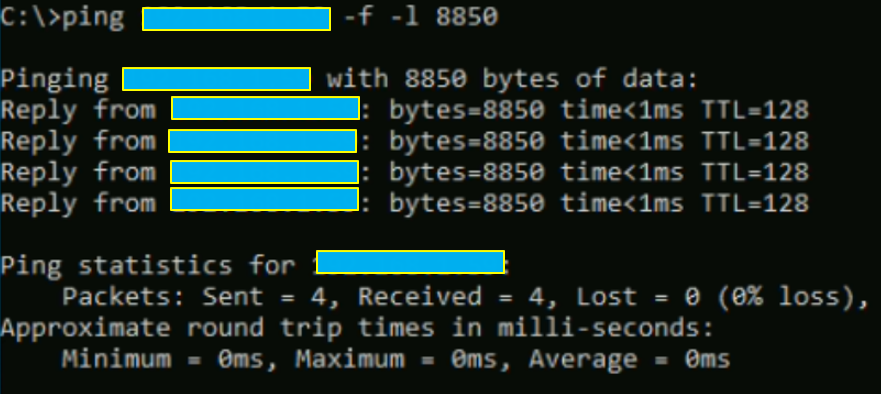
La configuration est bien OK.
A noter que vous devez avoir un message d’erreur tout à fait normal lorsque vous atteignez le MTU max.
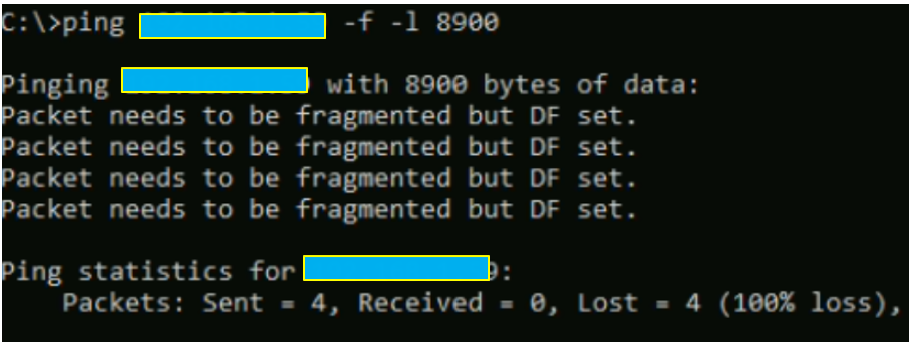
Côté tests « basiques » nous sommes bons.
Storage:
Comme je l’ai cité en début d’article, il faut vérifier chaque composant un par un. C’est donc au tour du stockage de subir des tests pour vérifier qu’il n’y a pas de goulot d’étranglement à ce niveau.
Sur cette suite de chapitres, je mettrai en avant certains points de performances sur le « VMDK Location », le RAID 0 et le RAID 1 sur du vSAN, voire du passthrough sur une VM mais qui, dans le fond n’ont pas d’impact direct sur le problème initial qu’est le problème de performances.
Aussi, pour rappel, la configuration du stockage des ESXi est :
4X Disque AG 1,6 To Enterprise NVMe U.2 Gen4 SATA 6Gbit/s (MTFDDAV480TDS) = 0,75 GB/s
12X Disque 3,84To SSD SAS ISE Lecture intensive 12Gbit/s (MZILT3T8HBLS0D3)= 1,5 GB/s
N.B : Les 2 VMs de tests « test-kevin-bp-limit-1 » et « test-kevin-bp-limit-2 » auront une configuration cette fois-ci de 16 vCPU et 128 GB Ram.
Vérification des Storage Policy vSAN
Dans ce chapitre, l’idée est de tester les performances des disques en mode RAID 1 sur un cluster standard (non stretched).
Voici la policy vSAN qui est appliquée aux VMs.
Premier benchmark : vSAN RAID 1 – Standard cluster with encryption

Comme vous pouvez le voir il n’y a rien de particulier, hormis le fait qu’il y ait le chiffrement d’activé.
Ce chiffrement est fait via le « Native Key Provider » que propose VMware depuis sa version vSphere 7.
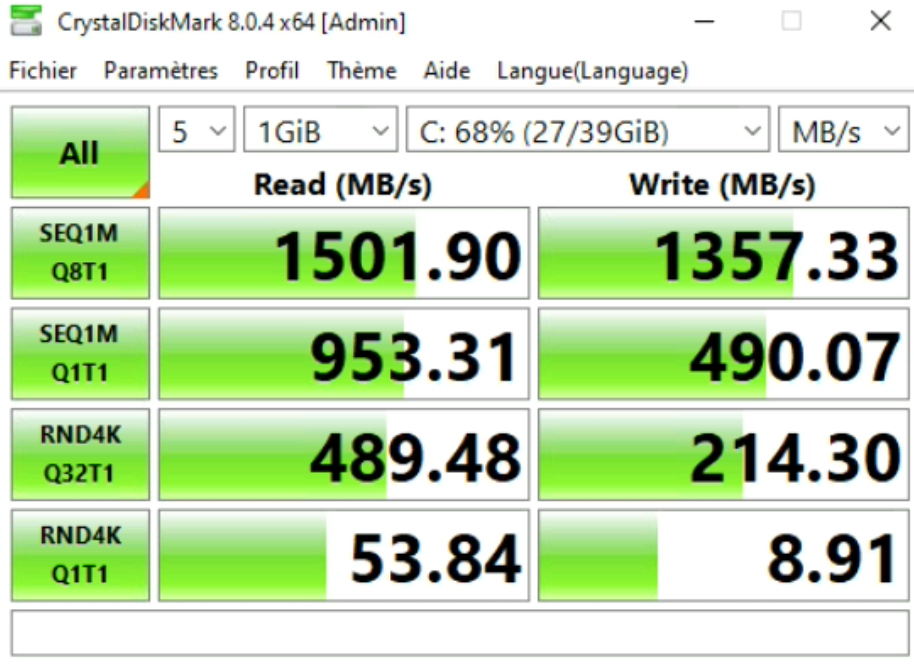
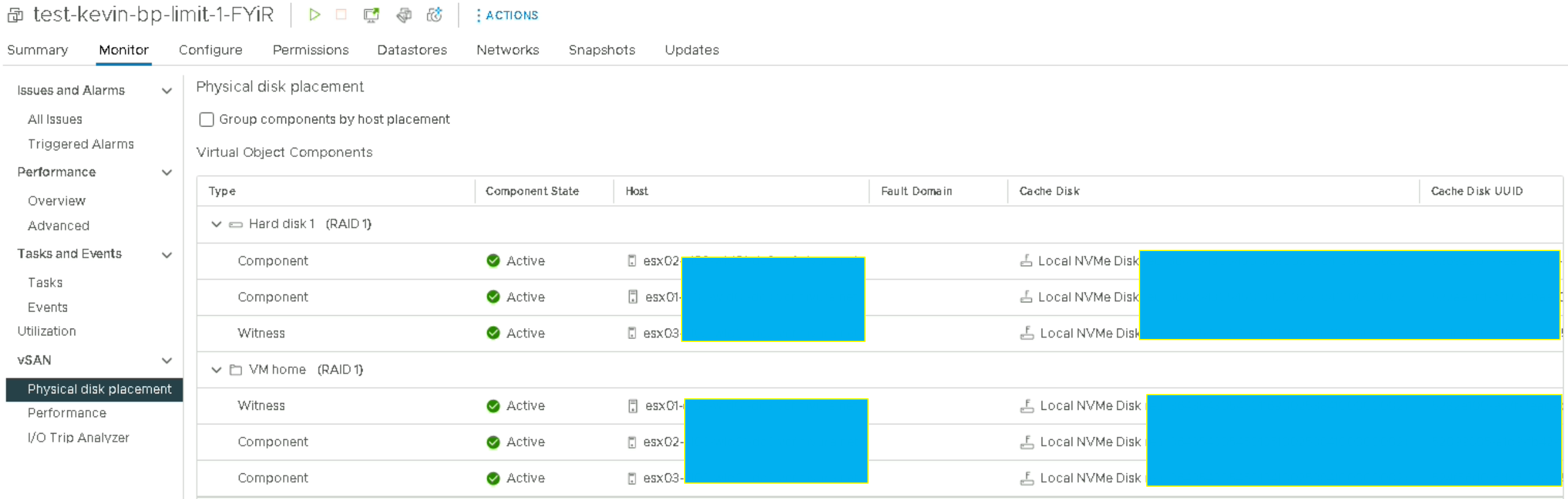
Ici, nous pouvons nous apercevoir que les vitesses correspondent bien à la norme SATA 6GBit/s (0,75Gbit * 2 disques/hosts « Object Replica » pour le RAID 1), et que la VM tourne bien sur les disques du « vSAN cache ».
Nous pouvons le vérifier mais l’idée de ce test est plutôt de voir si la VM atteint bien les performances que le serveur doit lui offrir, et c’est bien le cas.
Copie d’un fichier d’un répertoire vers un autre :
Outre le fait d’avoir des valeurs provenant d’un outil de benchmark, l’idée est de vérifier également en pratique ce que donne la vitesse de copie d’un fichier d’un répertoire vers un autre.
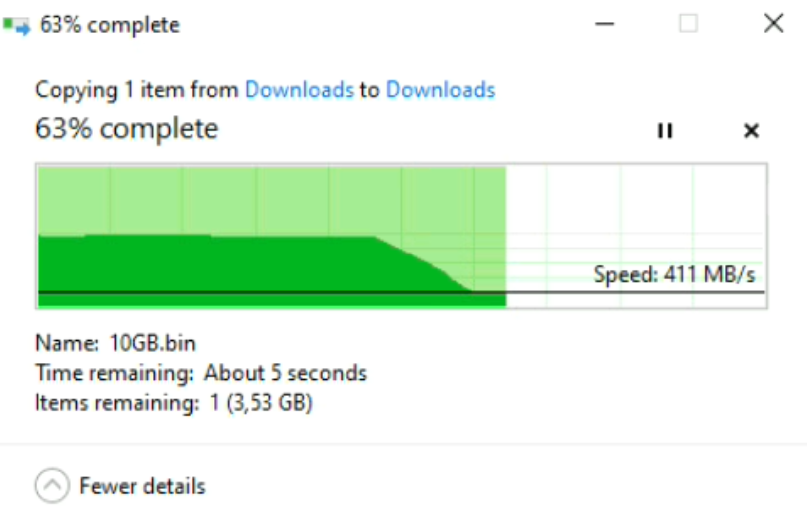
Encore une fois, les vitesses correspondent bien à la norme qui est de plus ou moins 750Mo/s théorique, et suivant les performances du disque.
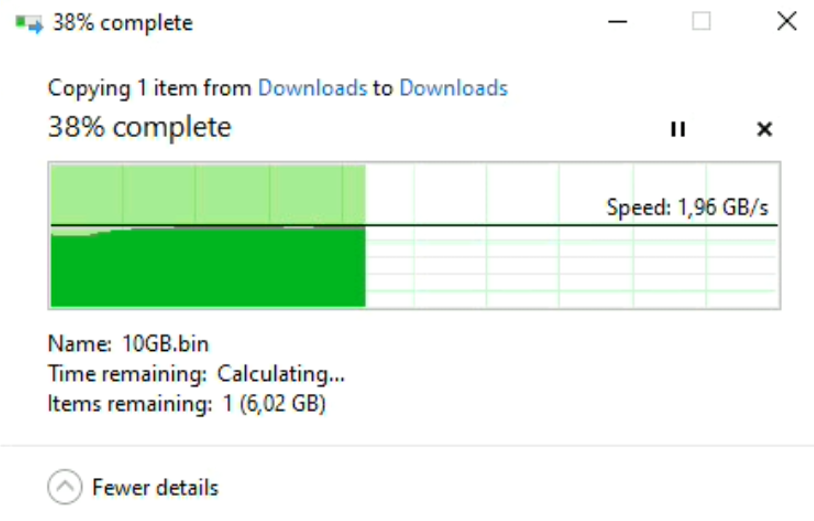
D’ailleurs, si nous copions à nouveau ce fichier dans un autre répertoire (ou au même endroit) nous aurons cette fois-ci des performances beaucoup plus élevées. Ceci est dû au fait que les données sont mises en cache côté RAM.
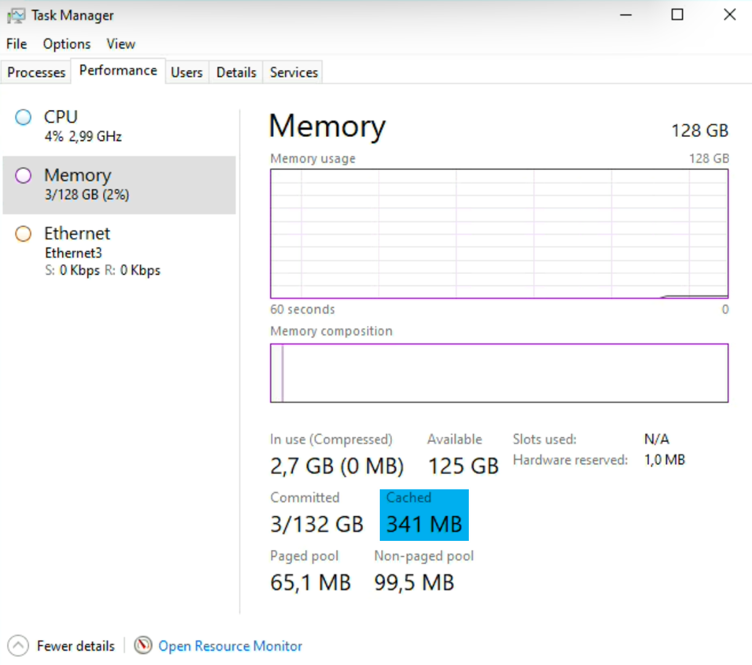
Pour le vérifier, un petit coup d’œil sur le « Task Manager » est nécessaire pour contrôler la quantité de données avant et après la copie.
N.B : Le fonctionnement du cache est indépendant du disque qui lui est rattaché (SATA, NVME, RDM,…)
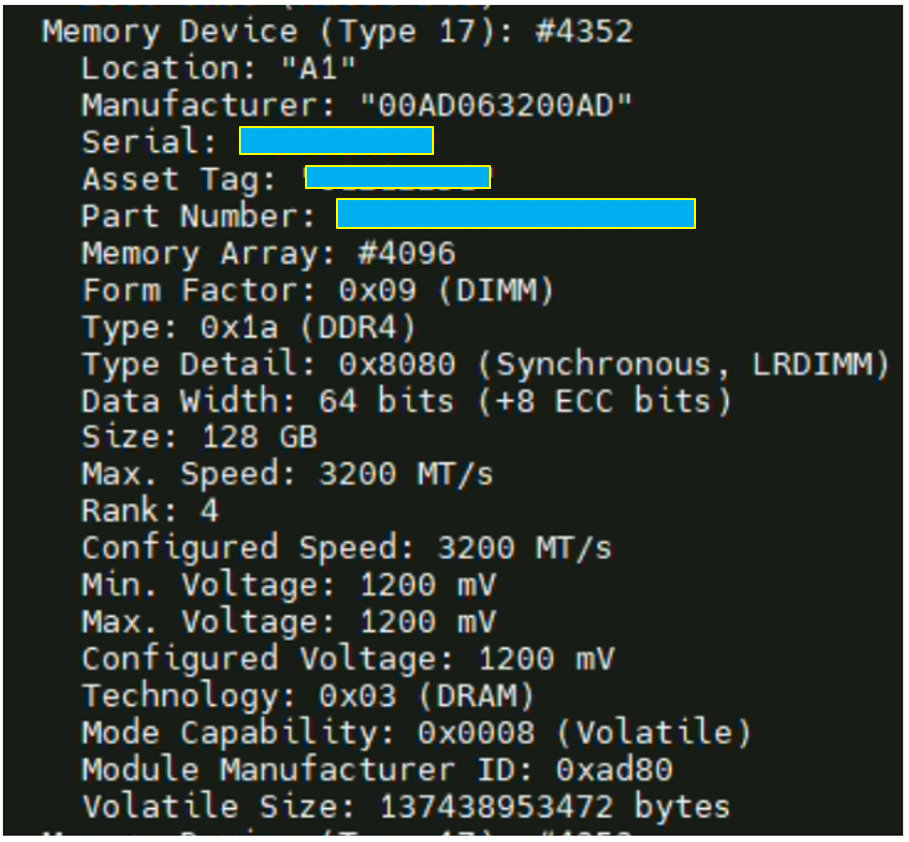
LRDIMM DDR4 : Vérification du « Data Rate » / « Peak Transfer Rate »
Pour vérifier le « Data Rate » de vos barrette et lister une partie du matériel sur un ESXi, il existe une commande : smbiosDump
Tips: Il existe une formule simple pour connaitre le « Peak transfer rate » d’une barrette de RAM.
Dans notre exemple, si nous prenons des barrettes LRDIMM DDR4 cadencées à 3200MT/s (Data Rate) elles auront une vitesse de ~25,6GB/s parce qu’il faut multiplier 3200 MT/s * 8 bits ce qui donne 25600 (à convertir en MB/s)
Data rate = Combien de bytes un module de RAM peut transférer
Peak transfer rate = Combien de megabytes un module de RAM peut transférer par seconde
N.B : Les barrettes physiques sont des 3,200MT/s. La copie ne pourra donc se faire au-delà de cette vitesse. Aussi, la vitesse d’écriture est bridée par celle du disque.
Pour être clair, dans une infrastructure, il y a toujours un maillon faible (goulot d’étranglement). Il peut soit être lié à la RAM, soit aux disques, soit au réseau, soit à l’OS ou voire même à plusieurs.
En pratique, le plus compliqué est de déterminer celui qui pose réellement problème, et pourquoi il le pose. Dans le cas de cet article, il s’agit de problème de performance qui, à première vue est identifié du côté réseau. Cependant, si nous ne vérifions pas composant par composant, il n’est pas simple de déterminer la cause et la résoudre. A moins, bien entendu, d’avoir à disposition une release note qui l’indique clairement par exemple.
Windows : RAID logiciel
Nous arrivons maintenant à l’OS et ses fonctionnalités.
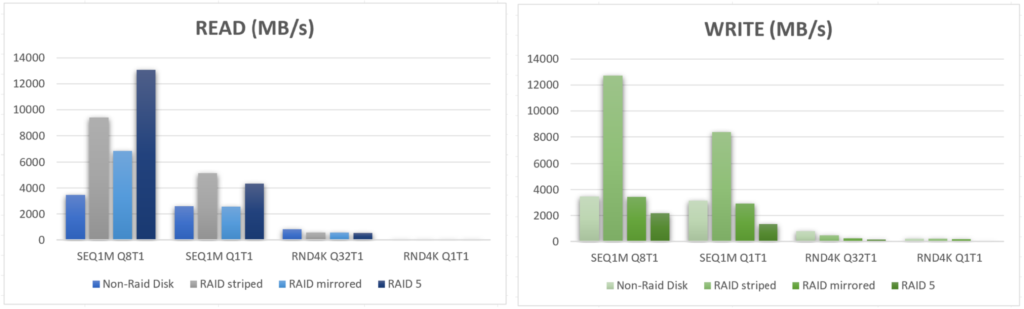
Côté Windows, et notamment sur un Windows de type « Server » nous pouvons monter un RAID5 logiciel, mais est-ce qu’il y a réellement un gain de performance avec un RAID logiciel ? Et est-ce que ce type de montage peut limiter un goulot d’étranglement sur la partie stockage ?
Globalement, Windows propose 4 modes qui sont tous basés sur du RAID traditionnel :
- Raid spanned
- Raid striped
- Raid Mirrored
- Raid 5
Tout d’abord, il faut ajouter 3 disques supplémentaires minimum à la VM.
Dans notre cas, nous en allons en ajouter 3 afin de pouvoir effectuer la mise en place du RAID5 sur le prochain test. Il suffira par la suite de les agréger sur le gestionnaire de disques côté Windows.
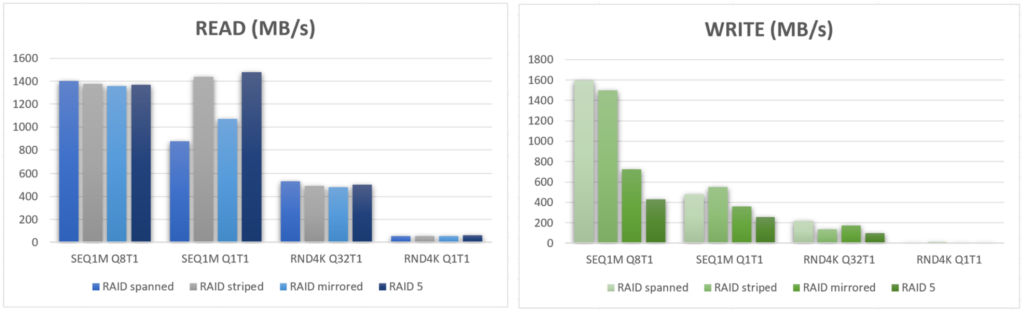
En lisant ces deux graphiques, nous pouvons en conclure qu’il n’y a absolument pas d’avantage côté performances de créer un RAID logiciel sous une infrastructure vSAN. Mais il faut savoir que Microsoft indique que l’objectif n’est pas un gain de performance, mais bien un niveau de résilience des données augmentés sur certains de ses outils.
Continuons donc nos tests.
Cette fois-ci nous allons reprendre la policy vSAN qui a été configurés précédemment, mais à la différence que nous n’allons pas activer le chiffrement, et ce afin de vérifier s’il y a effectivement un impact sur les performances disques comme l’annonce VMware.
vSAN RAID 1 – Standard cluster without encryption

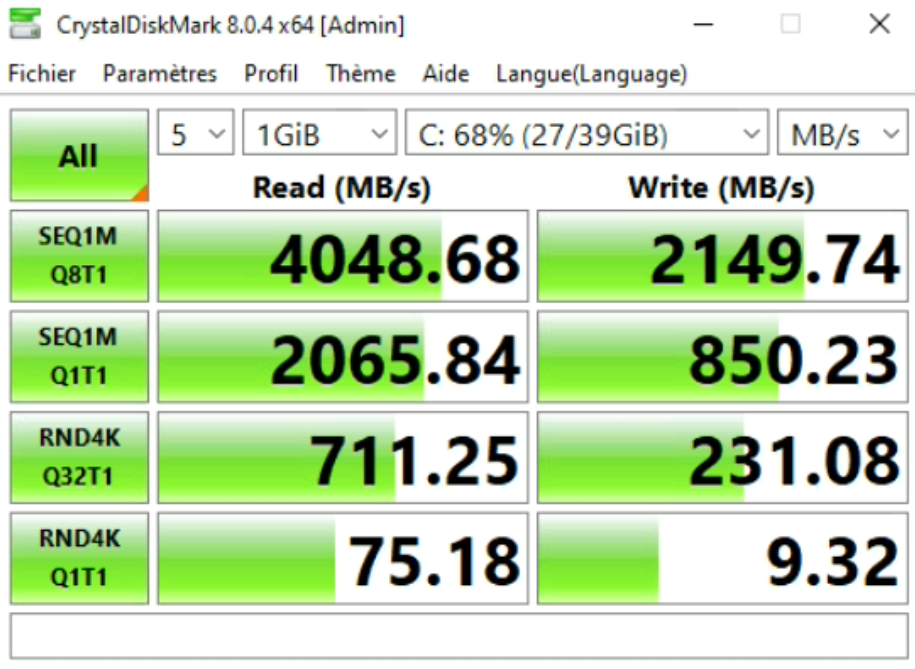
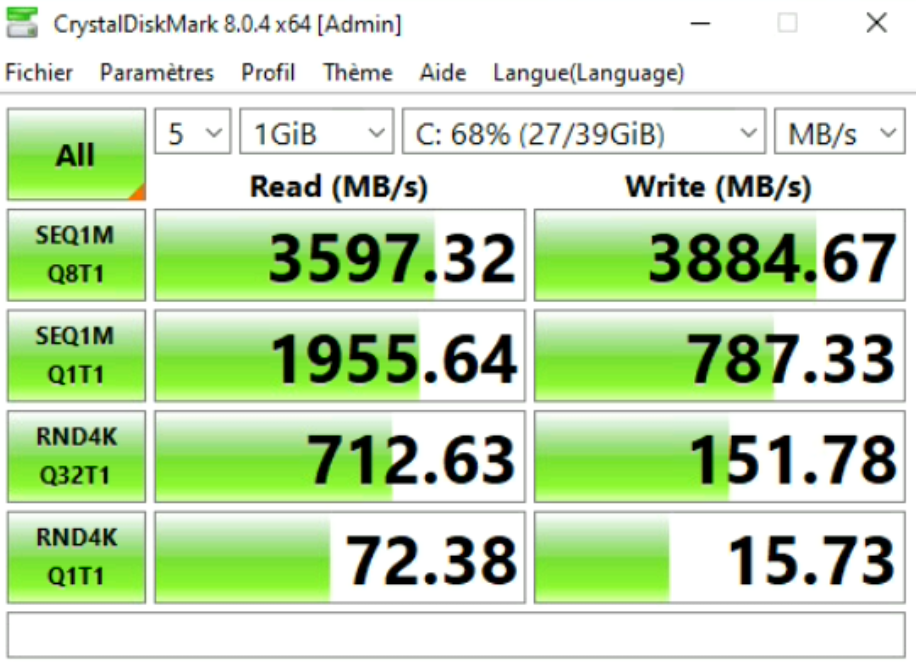
Au vu des résultats, nous pouvons noter un impact sur les performances des VMs lorsqu’elles sont chiffrées.
Sur le test précédent, nous avions 1501.90 MB/s en READ contre 4048.68 MB/s et 2149.74 MB/s WRITE MB/s contre 1301.23 sur les écritures séquentielles SEQ1M Q8T1.
Je pense que les disques de la VM doivent tourner cette fois-ci sur les disques du vSAN Capacity. Au vu de la norme (12Gbit/s) les valeurs sont très correctes.
Cependant un point sera à creuser pour un autre article.
« Pourquoi et comment fonctionnent les disques vSAN ?
J’ai effectué plusieurs fois des tests avec des arrêts relances des VMs entre chaque test pour vérifier les valeurs, et il semblerait que la VM sans chiffrement tourne tout le temps sur les disques de vSAN Capacity (les valeurs oscillent entre 3,7 et 4,1 GB/s) tandis que la même policy sans chiffrement les valeurs tournent tout le temps entre 1,1 et 1,5 GB/s) et ressemble plus à la normale 6Gbit/s qu’ont les vSAN Cache. »
Dans notre cas, il s’agit d’un chiffrement par VM, et non directement sur vSAN avec du « Data-at-Rest » et/ou du « Data-in-Transit ». Donc si nous faisons abstraction du paragraphe ci-dessus sur l’hypothèse du vSAN Capacity et du vSAN Cache, les pertes de performance sont de l’ordre de 270% en READ et 170% WRITE sur la même policy vSAN sans chiffrement, ce qui est énorme contrairement à ce qu’annonce VMware.
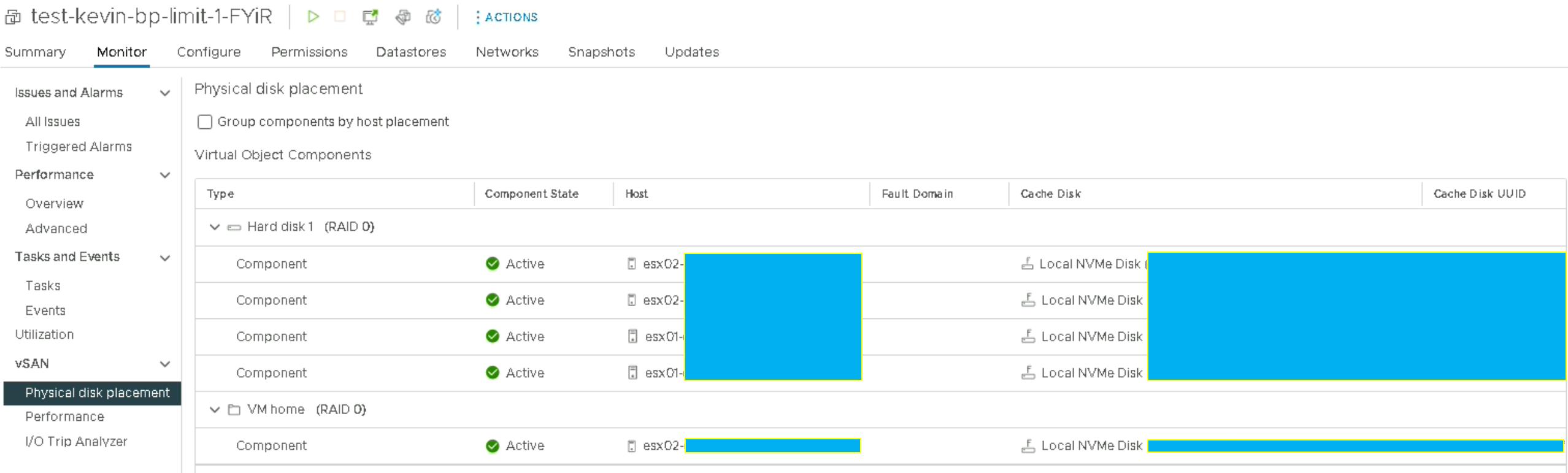
vSAN RAID 0 – Standard cluster without encryption and redundancy

Ici, le fait de passer à du RAID 1 vers du RAID 0 augmente considérablement la lecture du disque sur les gros fichiers. Dans les grandes lignes, nous doublons la vitesse possible mais c’est assez « logique » car c’est l’un des avantages de ce type du RAID 0.
Aussi, nous obtenons 3,8GB/s en READ parce qu’il faut additionner le nombre d’hosts sur laquelle est hébergée notre VM, et dans notre cas, les données sont réparties sur 2 ESXi. Il faut reprendre les données précédemment obtenues qui sont de 2,07GB/s * 2 disques (hosts) = 4,14 GB/s.
Evidemment, le calcul n’est pas aussi simple car il ne prend pas en compte les variations du disque à chaque instant par exemple, mais l’idée est là.
Passthrough NVME: de la performance pure
Ce chapitre est un complément des précédents, il n’est pas directement lié au problème de performance que nous rencontrons.
Cette fois-ci, les tests ont été effectués sur une infrastructure « basique », c’est-à-dire un simple ESXi standalone équipé comme suit :
ESX 8.0
AMD Threadripper 3960x
128Go DDR4
4x 1To NVME (PCie Gen4)
L’idée est de démontrer l’utilité du mode passthrough dans certains cas, et des performances possiblement atteignables avec ce mode.
N.B : activer du passthrough sur une VM désactive plusieurs features
A quoi sert le mode passthrough ?
Tout d’abord à quoi sert le passthrough sur du NVME Storage ? Je parle bien de storage, parce que je vous l’accorde habituellement c’est utilisé essentiellement avec des cartes graphiques. Mais certains workloads notamment AI ou les workloads des AV Engineer doivent disposer de nombreux I/O tout en ayant une certaine résilience des données. C’est là qu’intervient ce mode, c’est-à-dire dédier des disques à des VMs en bypassant les limitations virtuels des ESXi.
Pour ce faire il y a 2 modes :
- DirectPath I/O
- Permet de dédier un périphérique à une et même VM, et dans ce cas il est impossible de démarrer deux VMs portant le même périphérique.
- Dynamic DirectPath I/O
- Permet de configurer des « Tags » sur les périphériques passthrough de façon à supprimer la dépendance d’une VM a un host. (voir le schéma VMware ci-dessous).
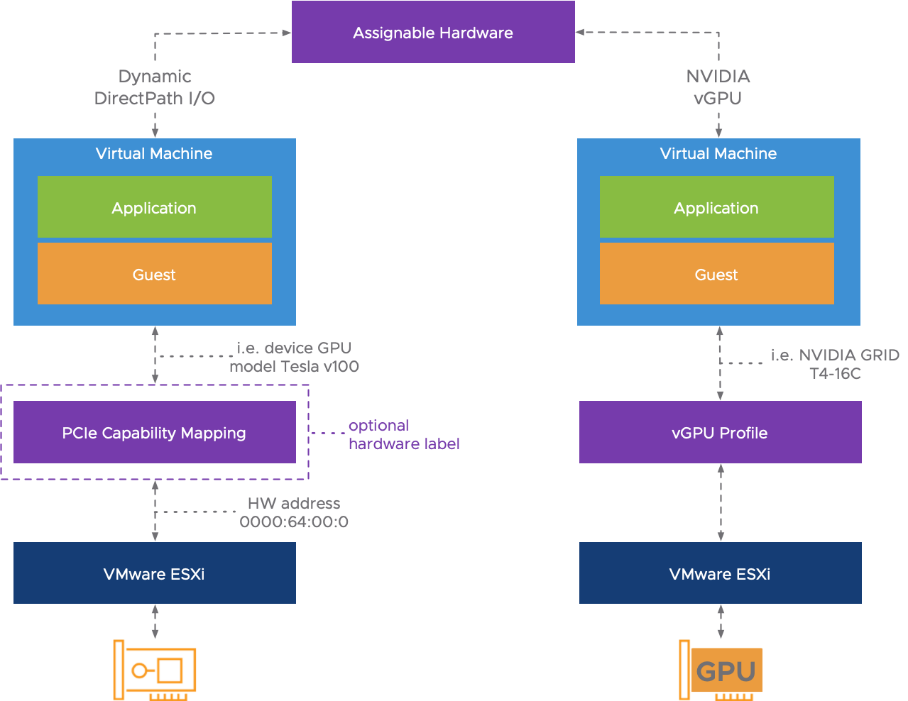
Schéma issue du blog VMware « vSphere 6 assignable hardware»
Conclusion :
Comme j’ai tenté de le démontrer tout au long de cet article, l’objectif est de vous donner une idée des points de contrôles à effectuer pour troubleshooter des problèmes de performance sur une infrastructure traditionnelle ou VCF.
Sur l’ensemble de ces tests nous pouvons noter qu’il n’y a pas de goulot d’étranglement côté stockage, et ce peu importe que la VM tourne sur les vSAN Cache ou les vSAN Capacity les débits sont très bon et répondent aux normes des connectiques sur lesquels ils sont montés.
Quant à la partie réseau les débits restent faibles sauf dans le cas où nous faisons des tests en loopback et lorsque nous passons directement par les VMKernel (bypass OS). Il semblerait donc que les faibles performances soient en partie due à l’OS (j’ai également testé avec une distribution Linux mais même constat).
Concernant le second article je n’ai, à date, toujours pas trouvé la cause du problème de performance mais une fois que la « root cause » sera identifiée je pourrai rédiger et publier l’article.
Pour conclure, et au vu des tests effectués je penche plus pour un problème de driver voire de la version ESXi.
A ce sujet le support VMware est engagé depuis plus d’un mois.
No responses yet