[ARTICLE] [VCENTER] [PART 2] Migration du Native Key Provider (NKP) vers un KMS Externe
Sur l’article précédent nous avons vu comment migrer nos workloads d’un NKP vers un KMS Externe et inversement, mais nous n’avons pas pris en compte les éventuels problèmes que nous pouvons rencontrer en PROD, où le moindre arrêt d’un workload peut être critique.
Migration failed => Workload KO
Après la migration des workloads du NKP vers le KMS Externe via le script:
Get-VM "votreVM"| Set-VMEncryptionKey -KMSClusterId "votreKMS"Il se peut que certaines VMs tombent en échec lors d’un re-key, et surtout si celle-ci a plusieurs disques.
Cela peut être visible directement sur le vCenter ou sur votre script si vous jamais avez inclus un test d’état OK/NOK avant de passer à la VM suivante.
Les causes possibles (confirmé avec des tests, et validé par le support VMware):
- vSphere HA VM Monitoring : Lors d’un re-key si la VM prend du temps à se chiffrer le vCenter n’a pas la corrélation avec la tâche en cours qui chiffre la VM, ce qui a pour conséquence un reset de la VM entrainant un échec de re-key
- C’est pour cela qu’il est important de vérifier chaque workload 1 par 1 après sa migration (logs vCenter, requête PowerCLI (Get-VMEncryptioninfo)
Message d’erreur de la VM sur “vmware.log“:
2023-03-10T15:16:22.314Z In(05) vmx - DISKLIB-LINK : "/vmfs/volumes/vsan:xxxxxxxxx-5exxxxxxx6/271xxxxxx3-xxac-xx91-xxa0-exxxxxxxx80/TEST-KEVIN-VM-2-lKPs.vmdk" : failed to open (Cannot decrypt disk because key or password is incorrect).- Le vCenter ne trouve pas le KMS Externe suite à un problème de communication entre les deux
Message d’erreur du vCenter sur “hostd.log“:
--> com.vmware.esx.trusted_infrastructure.kms.providers.not_found<The provider 'nom-du-kms-externe' does not exist.>Réponse du Support VMware sur l’ordre de chiffrement d’une VM:
- got new key from key provider ->
- save new key to keycache ->
- get old key from old keyprovider ->
- decrypt kdk with old key->
- use new key to encrypt kdkWorkaround 1: Unregister / Register VM
Ce premier workaround permet de reset le vmid de la VM et donc de forcer l’ESXi à demander la KEK au KMS via la KEK ID
Note de VMware: How vSphere Virtual Machine Encryption Protects Your Environment
If you delete or unregister an encrypted virtual machine, the ESXi host and the cluster remove the KEK from cache. The ESXi host can no longer use the KEK. This behavior is the same for standard key providers and trusted key providers. - Remove from inventory
- Vérification des fichiers sur le datastore
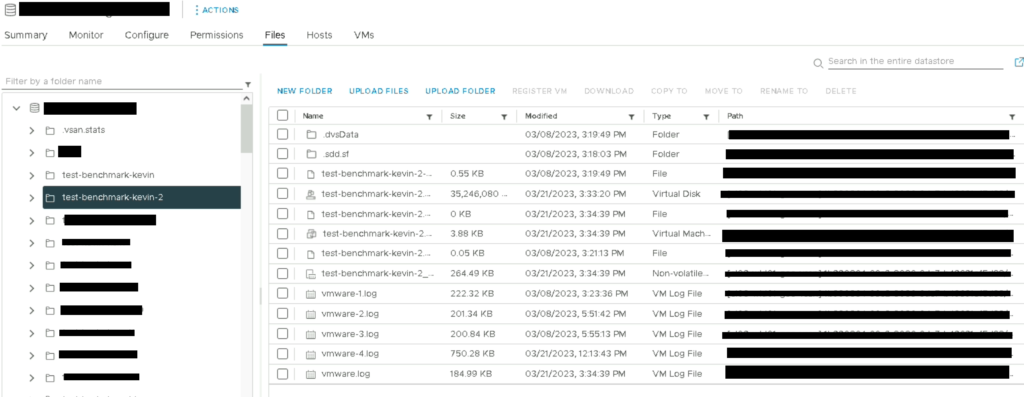
- Register VM
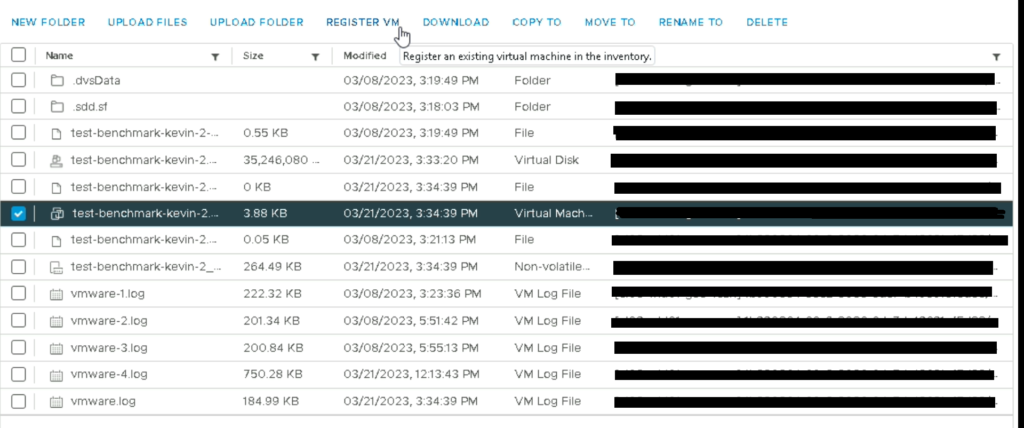
L’effet de bord de cette action est la perte d’historiques de la VM côté vCenter/vRops (performances, events, tasks). Cependant les fichiers “vmware.log” existent toujours à la racine de la VM dans le datastore, il sera donc à minima possible de récupérer les events via ces fichiers mais ce sera toujours moins productif qu’une vue graphique sur le vCenter


Workaround 2: Reload du .vmx
Contrairement au workaround 1 celui-ci est celui ayant le moins d’impact parce que vous ne perdrez pas l’historique de la VM que ça soit sur le vCenter (performances, events, tasks) ou sur le vRops parce que le “vmid” restera le même.
Il faut donc récupérer le vmid de la VM en question via:
vim-cmd vmsvc/getallvms
Une fois cet ID déterminé il faut simplement remplacer “getallvms” par “reload” en indiquant l’ID
vim-cmd vmsvc/reload 62
Workaround 3: PowerOff des VMs (préconisation VMware)
Ce workaround est celui qui est le plus contraignant (impact de service + update obligatoire du vCenter avec un patch qui doit sortir officiellement dans quelques mois) et il fonctionnera à condition que les 2 Key Provider soient joignables à tout moment pendant l’opération de migration.
1.Upgraded the vc to 70p07 21267547 (not released yet)
2.Create vm1 on host with vm encryption policy
3.PowerON VM and rekey vm(Failed with: Not support: unable to shallow rekey powered on vm.)
4.PowerOff VM and shallow Rekey(success
5.Repeat these steps multiple times, VM doesn’t go in power off state.Workaround 4: Désactivation du “vSphere HA VM Monitoring only” en amont de phase (valable seulement pour les VMs ayant un warning critical de HA en cours)
Afin d’éviter un failed re-key sur les VMs ayant un warning vSphere HA nous avons 2 choix:
- Soit désactiver complétement le vSphere HA Monitoring sur le cluster (moins propre et moins safe)
- Et surtout nécessite une étude d’impact avant désactivation de cette option
- Soit créer une “VM override Rule” en incluant les VMs voulues (plus propre et plus safe)
Conclusion
Avant toute chose, le chiffrement et la migration de workloads sont une chose à ne pas prendre à la légère parce que la moindre erreur de process (voire un mauvais process identifié) peut amener à une perte de données instantanée et irréversible de la VM si vous n’avez pas de backup avant opération.
Sources:
How vSAN Encryption Works
https://docs.vmware.com/en/VMware-vSphere/6.7/com.vmware.vsphere.virtualsan.doc/GUID-37F9636A-7481-4486-AAA9-E0A1A49343A1.html
How vSphere Virtual Machine Encryption Protects Your Environment
https://docs.vmware.com/en/VMware-vSphere/7.0/com.vmware.vsphere.security.doc/GUID-8D7D09AC-8579-4A33-9449-8E8BA49A3003.html
Reloading a vmx file without removing the virtual machine from inventory (1026043)
https://kb.vmware.com/s/article/1026043
No responses yet