[GUIDE] Comment un cloud provider optimise les workloads de ses clients ?
Cet article a été rédigé pour Metanext vous pouvez le retrouver, ainsi que d’autres articles techniques sur Blog – Metanext
Chapitre 1: Qu’est-ce que vCloud Director et ses optimisations.
Chapitre 2 : Détail technique concernant les optimisations de vCD
vCPU Speed sur les « OrgVDC »
vCPU Speed sur les « VM Sizing »
Storage sizing des « Storage Policy»
Network quota
Sizing des « vGPU Policy »
Chapitre 3: vNUMA sur des workload GPU NVIDIA
Conclusion
Chapitre 1: Qu’est-ce que vCloud Director et ses optimisations.
Fleuron de VMware, vCloud Director (vCD) est la solution développée par VMware pour le Cloud Public permettant ainsi aux clouds providers de proposer une offre IaaS, Longtemps, vCD été utilisé par les clients comme du Cloud privé, ce n’est qu’à partir de la version 10 où vCloud Director a pris un tout autre tournant.
Aujourd’hui VMware investi une grande partie sur la branche technologique Cloud pour en faire une solution stable et fiable. D’ailleurs cela a donné naissance à plusieurs Cloud Provider sur le marché, et c’est sans compter l’enjeu grandissant des “Sovereign Cloud Provider” qui ont pu naître grâce à cette solution.
A ce sujet VMware délivre des homologations aux Cloud Provider respectant le cahier des charges VMware

Chapitre 2 : Détail technique concernant les optimisations de vCD
vCD a plusieurs paramètres d’optimisations pour permettre aux cloud provider d’optimiser leur capacity planning en trouvant le meilleur rapport performance/consommation des workloads.
- vCPU Speed sur les « OrgVDC »
- vCPU Speed sur les « VM Sizing »
- Storage sizing des « Storage Policy».
- Network quota
- Sizing des « vGPU Policy”
vCPU Speed sur les « OrgVDC »
Ce paramètre permet de limiter la consommation en « Ghz » sur chaque VM de l’OrgVDC, il est semblable au paramètre « CPU Limit » sur les VM côté vCenter.

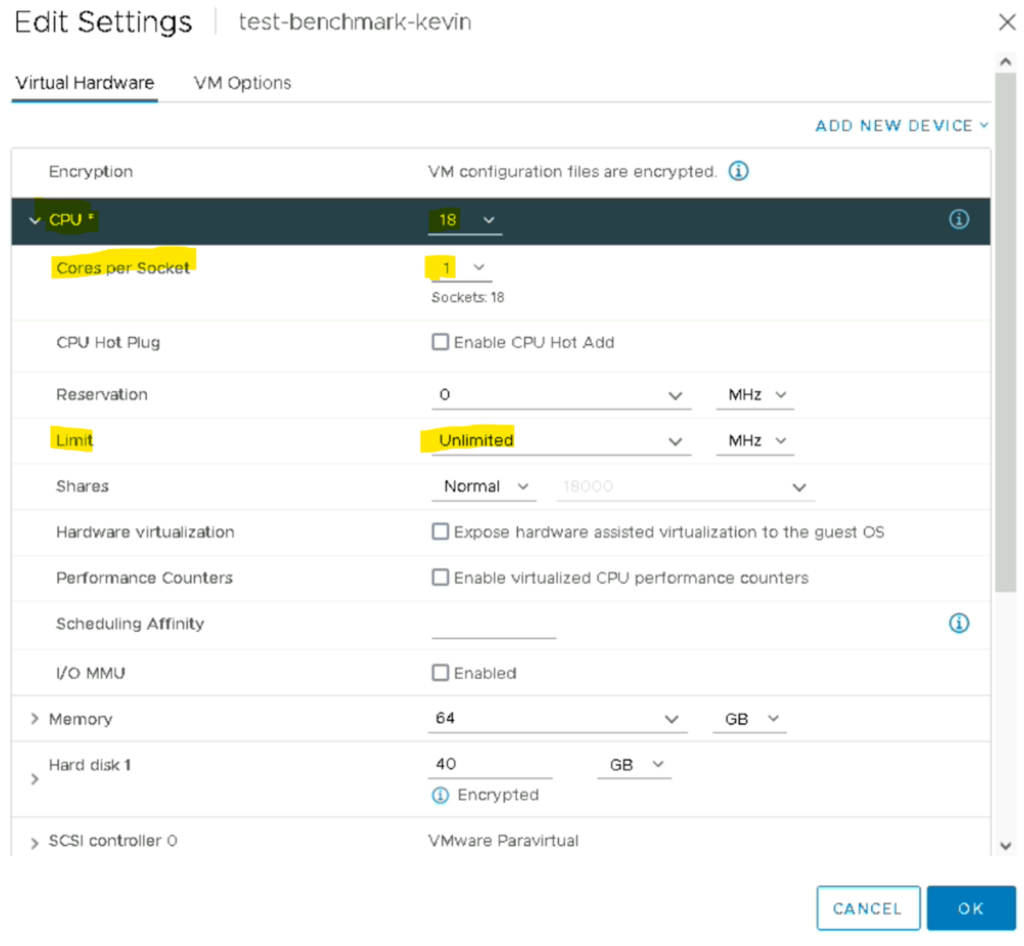
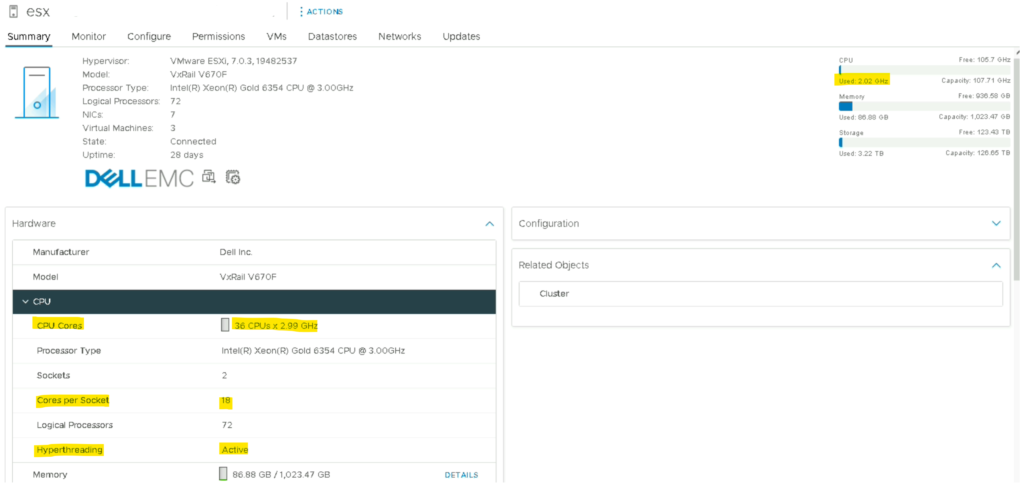
Exemple concret, en prenant notre ESXi de l’article précédent qui est un Intel(R) Xeon(R) Gold 6354 CPU @ 3.00GHz avec 18 cœurs par socket il faut comprendre que chaque cœur physique aura/pourra consommer 3Ghz.
Si nous prenons un cluster constitué de 3 nœuds Intel Xeon Gold 6354 nous aurons au total ~162 Ghz consommables.
(18 cœurs * 3 Ghz * 3 ESXi)
Dans le cas où ce paramètre n’était pas présent, même une VM de 18vCPU pourraient consommer l’ensemble de la fréquence du cluster.
N.B : Etant donné que l’hyperthreading est activé il faut multiplier le nombre de cœur par 2 (18 cœurs * 2 = 36 cœurs = 108 Ghz)
Voici la configuration de la VM sur le vCenter :
Exemple d’une VM avec un benchmark OCCT :

Consommation en Ghz de la VM
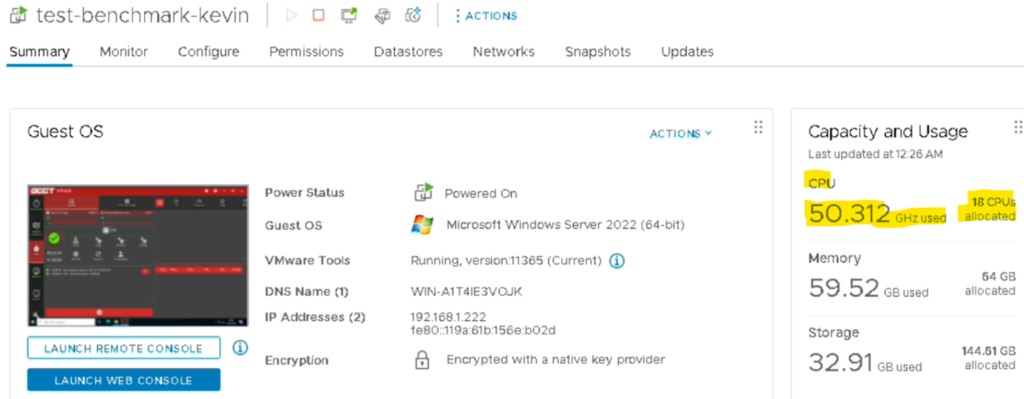
Consommation de la VM sous OCCT sur le vCenter
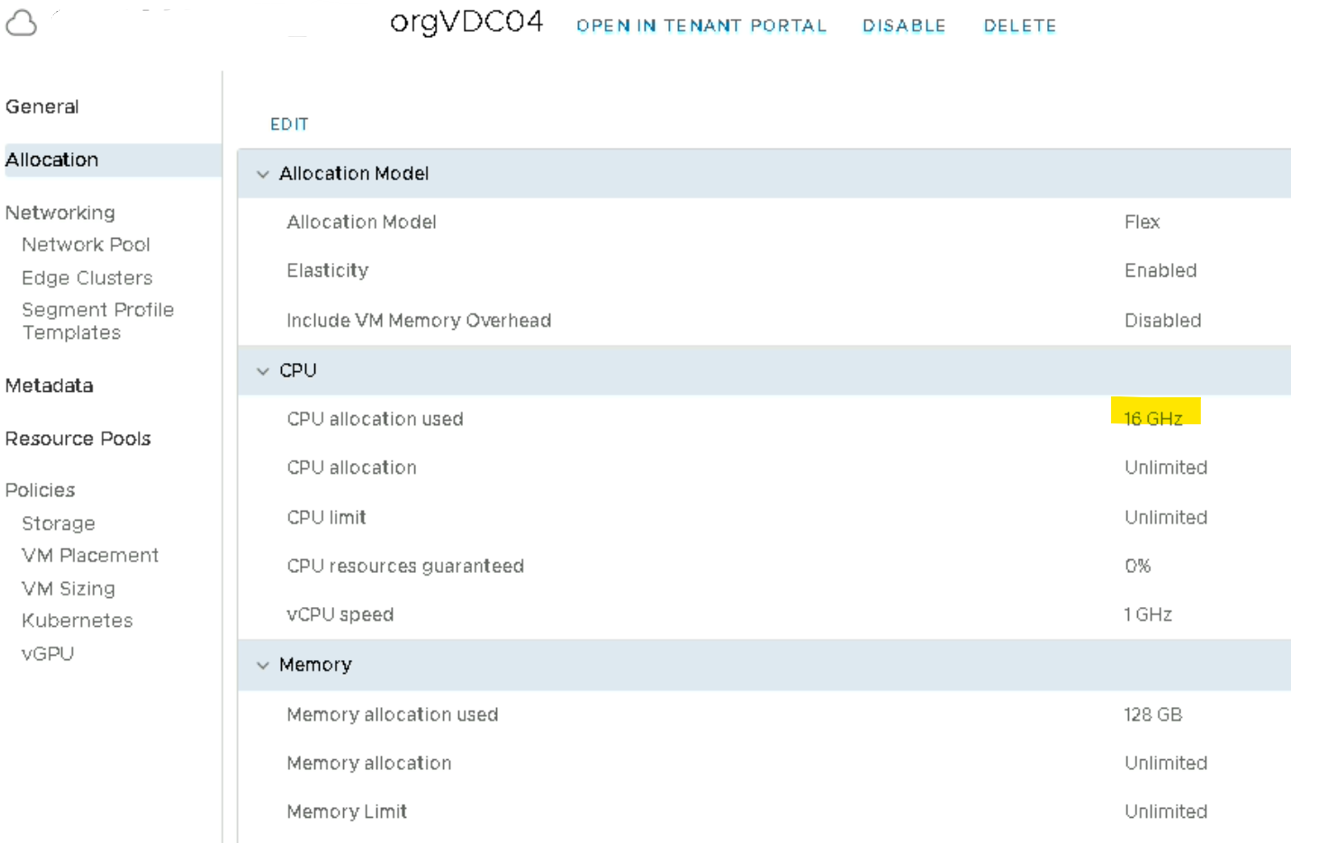
Côté vCD, au niveau OrgVDC, si le vCPU Speed est configuré à 1 Ghz cela veut dire que chaque workload présent sur cette OrgVDC se verra affecter une limite de 1Ghz par cœur, et peu importe que la VM ait 1 ou X vCPU.
Ici nous avons donc une VM avec 16 vCPU qui consomme 16 Ghz d’allocations sur le cluster
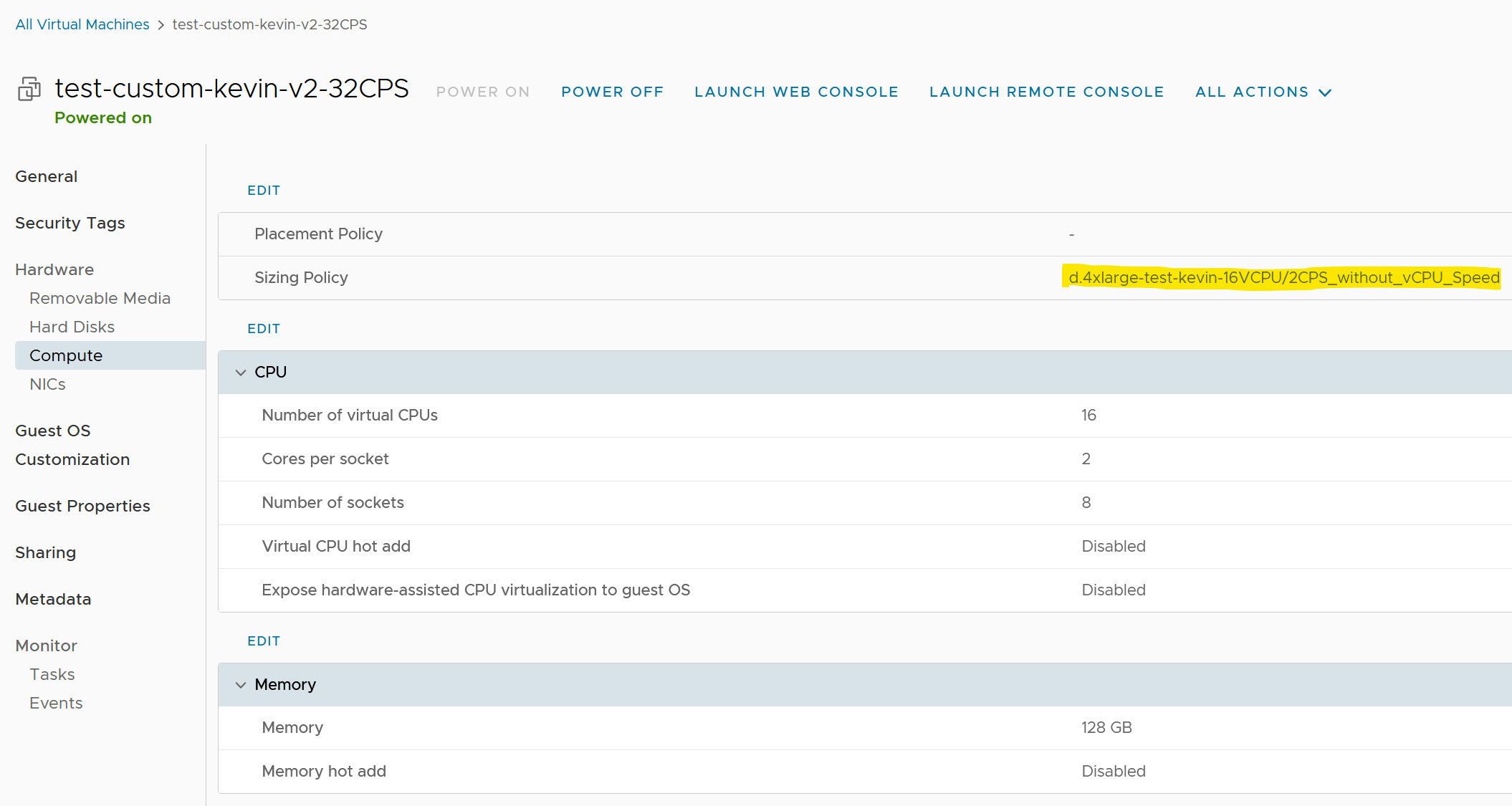
Nous pouvons aussi le vérifier sur la vue « provider » vCD. Vue, qui permet l’administration de l’infrastructure.
Deuxième exemple avec le même paramètre mais cette fois-ci à 10Ghz :
Nous configurons donc la même VM mais avec le « vCPU Speed Limit » à 10 Ghz. Ce qui, dans ce cas nous donne automatiquement 160 Ghz d’alloués sur le cluster mais qui n’est pas adapté parce qu’un ESXi peut contenir une VM ayant maximum 107.71 Ghz comme vu précédemment.
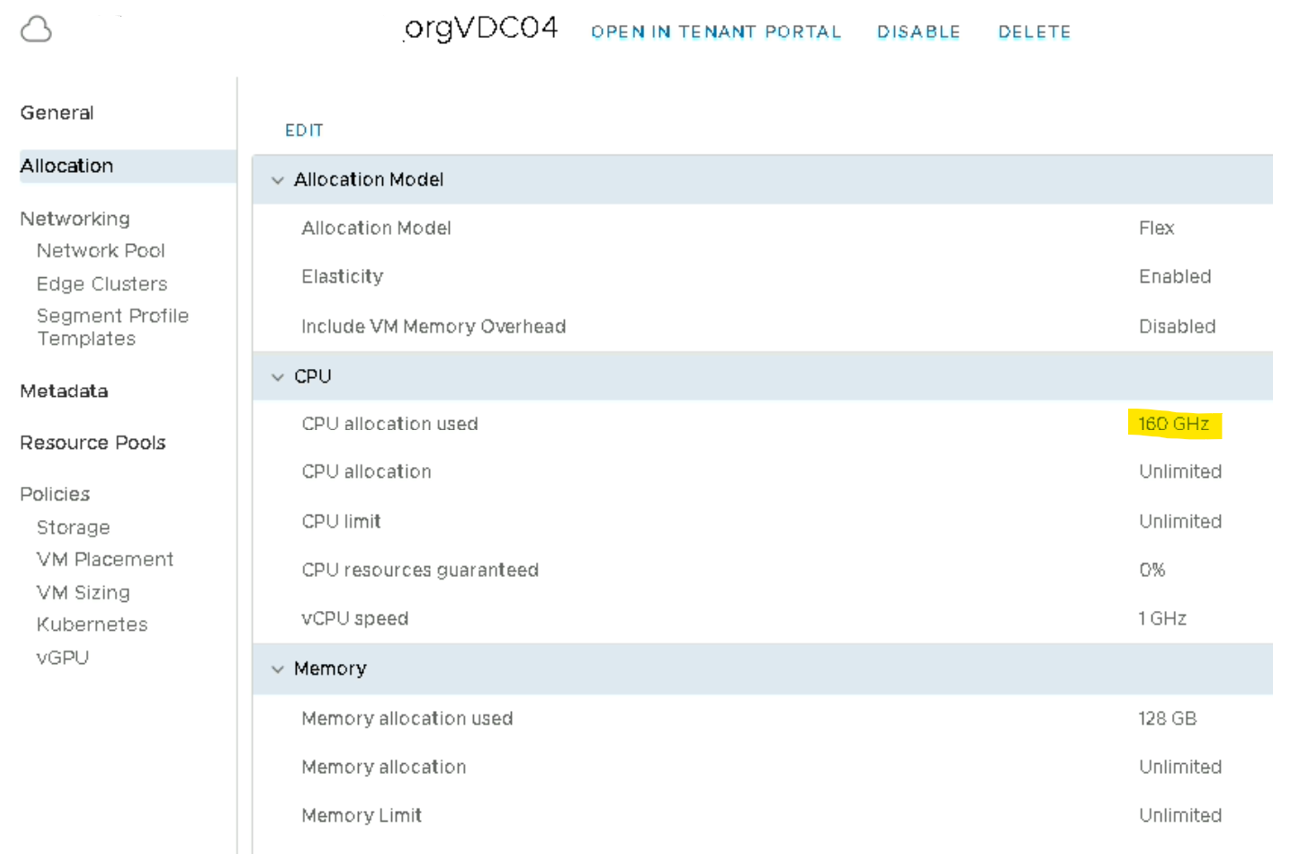
Nous pouvons affirmer que ce paramètre est indispensable, et encore plus dans le cas d’une infrastructure mutualisée comme un cloud provider où chaque mauvaise configuration peut vite devenir un gros problème (remédiation avec planification et arrêt des workloads dans certain cas) . Si nous prenons l’exemple de la VM ci-dessus avec une limite à 10Ghz la VM pourra consommer plus de CPU/Ghz que ce que propose le cluster, imaginez-vous quelques minutes que cette VM se fasse compromettre. C’est une infrastructure de production qui peut être perturbée par une mauvaise configuration complexe à identifier, dans le sens où très peu de workload consomme autant, sauf les outils de benchmarks qui eux n’ont pas de limite à par celle du physique.
vCPU Speed sur les « VM Sizing »
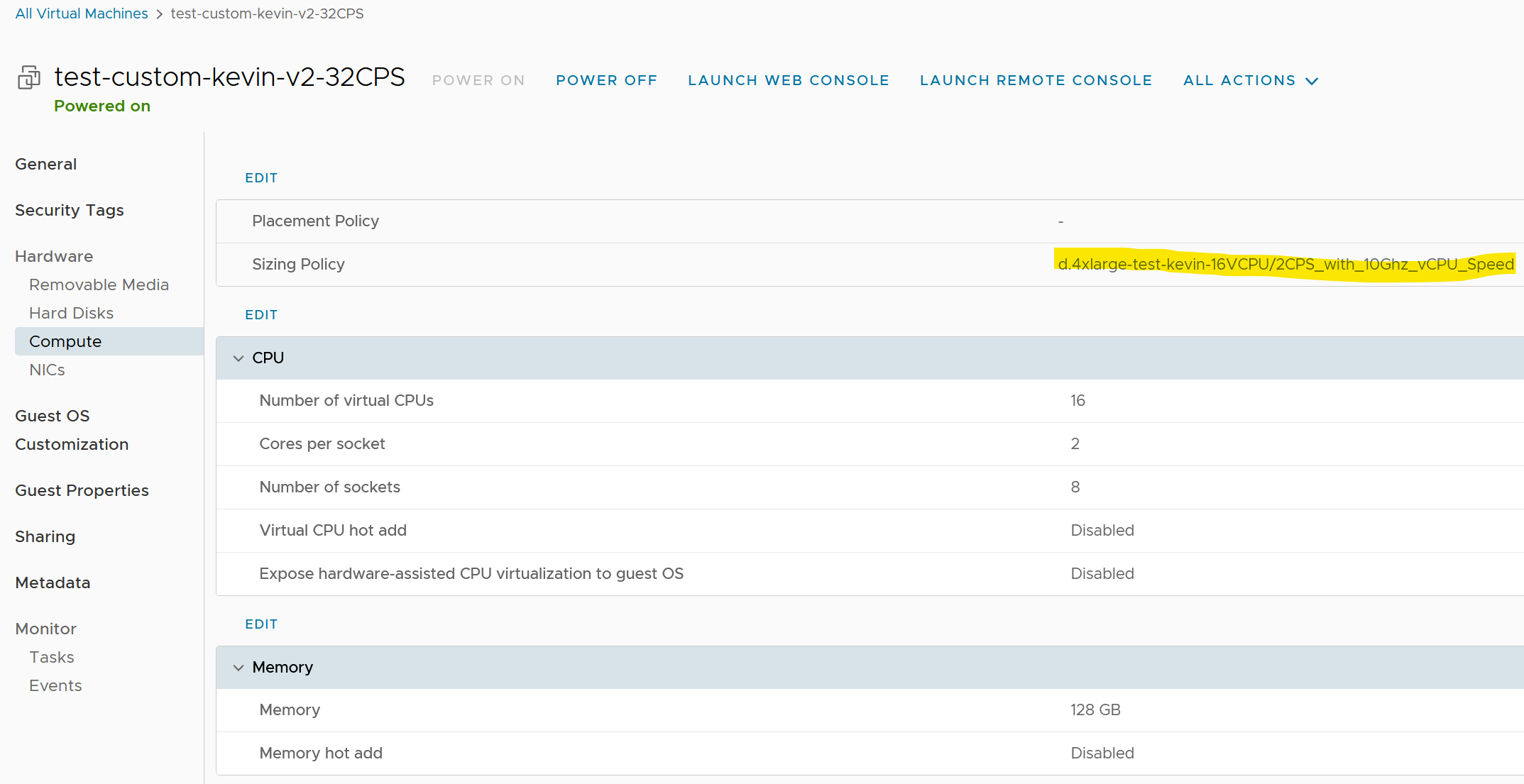
Le paramètre « vCPU Speed » a le même effet que le « vCPU Speed » mais au niveau des VM Sizing directement lié au gabarit de la VM.
L’idée de ce paramètre est de pouvoir dimensionner la consommation en fréquence (Ghz) en fonction de la taille du profil (meilleure rapport peformance/capacity planning).
NB : sur la version vCD 10.3.2 il y a un bug d’affichage sur « CPU allocation used » il faut éteindre puis rallumer la VM pour que l’ancienne valeur d’allocation soit remise à zéro et que la nouvelle s’affiche
- Si par exemple une VM tourne avec 8 vCPU sans vCPU Speed sur son VM Sizing et qu’on l’éteint cette VM puis qu’on change son gabarit par un 16 vCPU c’est toujours la valeur de 8 Ghz (8vCPU) qui est affichée. Il faut allumer la VM une première fois puis l’éteindre pour que cette valeur « CPU allocation used » soit mise à jour.
Storage sizing des « Storage Policy».
Ce paramètre permet quant à lui de limiter les ressources de stockage qu’une OrgVDC peut consommer sur le cluster.
Exemple :
Si nous avons un cluster vSAN de 700To nous avons possibilité de limiter tous les workloads de l’OrgVDC à 20To maximum. (Evidemment pour les exemples ci-dessous je ne prends pas en compte les limitations OS sur le storage sizing)
- Une VM Windows de 10To
- Une VM Linux de 5To

Même principe avec une VM qui se ferait compromettre, et auquel aucune limitation sur l’OrgVDC n’a été posée, elle pourrait donc très bien consommer l’ensemble des ressources stockage du cluster.
Network quota
Nous avons évidemment la possibilité de limiter les ressources côté network.
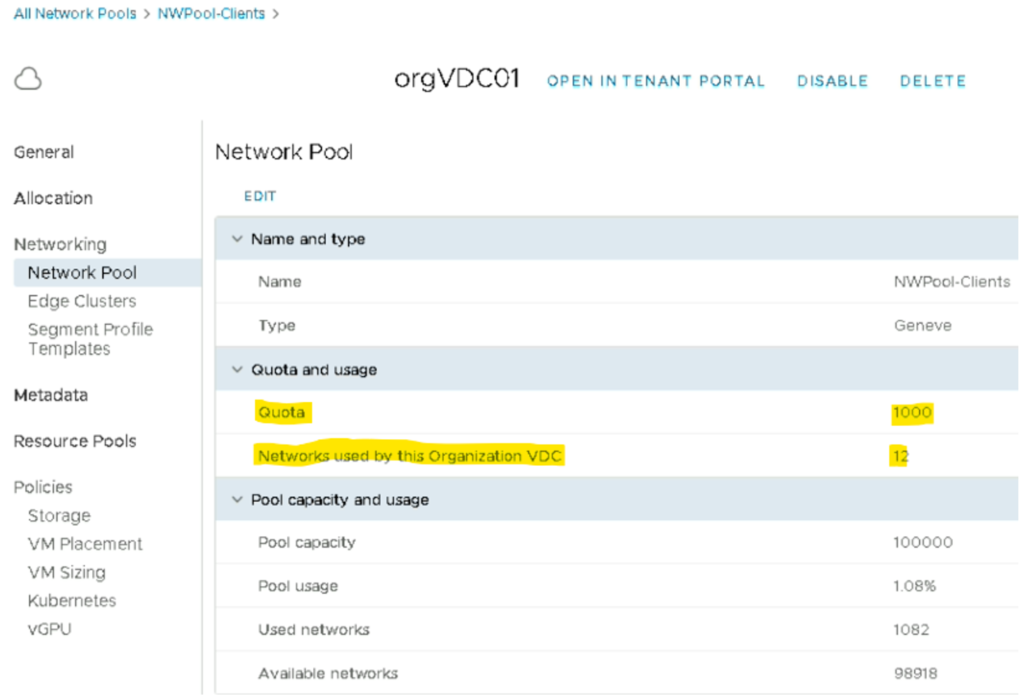
N.B : sur la version 10.3.2 de vCD il y a un bug qui fait que le compteur network ne fonctionne plus lorsqu’un DCGroup est configuré au niveau du tenant.
Sizing des « vGPU Policy »
Les vGPU policy ont les mêmes effets que les VM Sizing à la différence que sur les vGPU Policies il y a un VM Group à définir (VM/Host group côté vCenter) afin de regrouper les VMs au sein d’un ESXi.
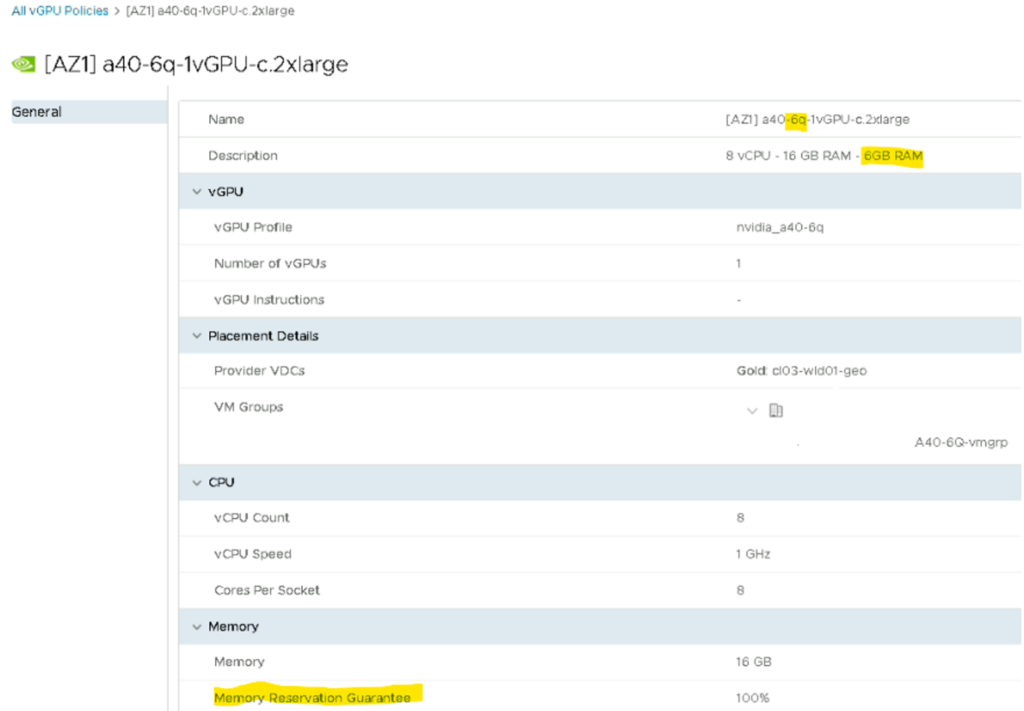
N.B : Les VM ayant un profil vGPU ont obligatoirement une réservation côté RAM ESXi et RAM GPU.
Si une VM a un profil 8Q qui correspond à 8Go de RAM elle aura 8Go réservée sur l’ESXi/Carte graphique qui porte ce workload
Chapitre 3: vNUMA sur des workload GPU NVIDIA
Il existe très peu de littérature sur le sujet, autour de la topologie vNUMA et GPU Nvidia. Dans la continuité des tests, nous allons découvrir dans cet article le lien entre les deux
Pour rappel l’infrastructure pour nos benchmark est la suivante :
– Intel(R) Xeon(R) Gold 6354 CPU @ 3.00GHz (2x CPU physique)
– Cores per socket : 18
– Logical Processors: 72
– Hyperthreading enabled
– RAM: 1024Go (à diviser par deux, 512Go par socket)
Comparaison des benchmarks :

Ces variations sont très certainement dues à une charge côté VM ou ESXi, nous pouvons donc en conclure qu’il n’y a aucune différence de performance sur une VM ayant un profil GPU attaché ou non mais il est aussi à noter que cela va dépendre des softwares qui vont être utilisés par la carte vGPU.
N.B : Ces tests ont été effectués à travers vCD mais le concept reste le même s’ils avaient été effectués sur le vCenter (la différence entre un workload GPU et non GPU est l’association d’un device PCIe).
Conclusion
Il est à noter que l’ensemble de ces benchmark couvre une grande partie des use cases/workloads que peuvent avoir des clients de Cloud Provider et également des infrastructures on-premise (CPU, chiffrement, traitement vidéo avec ou sans CUDA,..) mais ils ne peuvent représenter la réalité en tout point étant donné qu’une infrastructure est majoritairement composée de workload hétérogène, cet article est donc là pour vous aider à trouver le bon compromis entre performance et optimisation de votre infrastructure mais des tests sont indispensables sur l’infrastructure en question.
A vos tests ! ^^
No responses yet